Thread #108269922

File: Screenshot_20260301_165203_Waterfox.jpg (123.5 KB)
123.5 KB JPG
Why the fuck do people not run their own AI locally?
It's not that hard and you get to keep your prompts private. I never understood why people keep sending their prompts to a company.
135 RepliesView Thread
 Showing all 135 replies.
Showing all 135 replies.>>
>>
>>
>>
>>
>>
>>
>>
>>108270047
>Don't I need at least 5 figures to get equivalent level performance?
no amount of money will get you equivalent level performance. chinese benchmaxxing is not representative of real performance. just try it yourself and it will be obvious.
>>
>>
>>
>>
>>
File: Utopya_70014.jpg (49.7 KB)

49.7 KB JPG
because fake ratings and fake stats only attract retards, they kinda think its a room full of people while its filled with bots (automated accounts)
reminder that acktropic has more likes on github than linux does. it wasnt popular then, it is not popular now
>>
>>
>>
>>
>>
>>
>>
>>
File: 1771840537266182.png (286 KB)

286 KB PNG
>>108270094
>according to Dario
>>
File: 16176546454372727.gif (23.4 KB)

23.4 KB GIF
Because people are not willing to drop a few dozens of thousands of bucks in order to create bullet-points for their powerpoint slides?
Because people are sitting with 8/16gb ram and low/mid gpus or even igpus on their actual home computers?
Because tiny models which can technically run on those average consumer home computers are a complete dogshit compared to a 20 buck/mo models offered by companies?
Consumer computers are decades behind in terms of LLM capabilities.
For local LLM take to be valid - you should be able to afford something like 5090+256/512 gigs of ram for like 2k bucks - that is not happening for many years to come. And as models are getting more complex and larger - consumer hardware will never catch-up to a dedicated data center.
>>
>>108269922
You can't run it on your phone.
Most people are normalniggers and want things that "just werk". If you tell someone that you can set up a computer in your home and have your own personal AI they'll think you're a weirdo also a pedophile and you're antisemitic and do not want to give the Chosen Ones their cut
>>
>>108270490
>Because people are not willing to drop a few dozens of thousands of bucks in order to create bullet-points for their powerpoint slides?
>Because people are sitting with 8/16gb ram and low/mid gpus or even igpus on their actual home computers?
I use a rig with my old 1080ti in it and it Just Werkz™ with 16B models.
>What, do you need more?
>>
>>
>>108270490
>Because tiny models which can technically run on those average consumer home computers are a complete dogshit compared to a 20 buck/mo models offered by companies?
These models aren't any better. You just need to prompt better. The additional power offered by them is almost entirely wasted by 99% of prompts because people think they can talk to it like a person and not instruct it like a manager.
You also don't need this much power if you're just asking it to code small snippets, generate and fill out forms, or finding patterns in images. You can also use different models and swap out for specialized models on the fly for the task you're trying to accomplish.
The generalized models actually suck when you realize that most of their power is made to tardwrangle humans and keep them from saying nigger. It's not useful power that is beneficial to you. For that, you want specialized models that you swap out.
>>
>>
>>
>>
>>108270603
Yes, your ability to use technology is probably from the 90s, possibly the early 2000's.
>YOU DON'T UNDERSTAND, I _NEED_ IT TO BE BETTER AT UNDERSTANDING MY BARELY LITERATE SCREEDS
No you don't, and I doubt you have, even once, managed to cobble together a prompt that uses even 5% of the capabilities of a 12B model.
>>
>>108270659
Just when I thought you couldn't possibly sound more Indian you suddenly flaunt your "proompt engineering skills".
Ah, It's no wonder you felt so personally attacked when I started talking about retards on /g.
>>
>>108270636
ok valid point..
But local AI is getting pretty good. I can run qwen3.5-35b-a3b on a 3060 12GB and 32GB Ram (5y old pc) and it runs pretty good. Not super fast but decent.
It used to be difficult setting this up locally, you'd always bump into vram issues but now it offloads to ram fine.. running lmstudio
>>
>>108270588 >>108270566
How do you create a proper specialized model? Of course, it makes sense to have, for example, dedicated model which just does one programming language or just one topic / task type. I can see how some tiny 2-20B highly-specialized model can beat the shit out of all-in-one monstrosity - but how to get there?
Because this is literally what I'm doing with said commercial models - instead of general chats I use these "custom gpts" to limit their model right now.
>>
>>
>>108270674
And here we see the final cope: "ur indian..."
You think you need Claude or Gemini because you ask short, vague questions to AI because you don't realize that this isn't a thinking person. It doesn't understand what you are saying. You give it prompts to provide context so you can ask it a question around the prompt you gave it.
> you suddenly flaunt your "proompt engineering skills".
And this is how I know you can't even put models like Claude to good use, because you think this is some kind of fake skill. Most people would be fine with 8B models if they were taught how the fuck to use them.
>Ah, It's no wonder you felt so personally attacked when I started talking about retards on /g.
Maybe stop talking about yourself so harshly, next time. I'm only trying to help.
>>
>>108269922
Because it costs over 15k in hardware to even run a decent model with moderate performance locally. To get the best model with good performance you are looking at at least 30k and that isn't including operating costs.
>>
>>
>>108270696
>How do you create a proper specialized model?
Personally I don't create mine, I use hugging face. But what you do if you want to take the shortcut in making specialized models is starting with a baseline and adding a LoRA on top of it
https://huggingface.co/docs/diffusers/training/lora
tldr the base model is the main meat of the AI, while the LoRA is more like a mod that you add on, and you stuff that mod with the things that are tailored to you or are trained on things you do. You can use pytorch to do that or huggingface has a very simple guide to creating one.
You can also get a base model and use other people's loras. And you'll find fine-tuning models by adding Loras to them is superior to trying to make prompts and keywords that are better for the AI to digest.
>>
>>
>>108270703
I'm absolutely capable of providing a model with the context it needs to solve a problem. The difference is that if you provide opus 4.6 with the same context and ask it to solve the problem, it will do much better. It won't require 6 follow up prompts correcting it. You won't run out of context adding more information either.
Using a local model is like using stone tools - sure, technically, you might eventually get the job done, but why would you?
>Muh privac-
My bosses don't care.
>>
>>
>>108270719
>so you think prompt engineering is still needed for latest models?
I'm saying you don't NEED the latest models if you use some intelligent prompting because, if you were informed how they worked, you would realize prompt engineering is still happening to even Claude and Gemini. It's just been abstracted out with scripting because they're aware most people who are using them are fucking retards who don't use AI correctly to begin with.
Like you!
If you took the time to educate yourself, you'd be fine with 12B models, still. The new models are only impressive because a person smarter than you did the legwork behind the scenes.
>>
>>108270588
Oh my God, the cope.
I just tell my Claude based assistant what to do and it just does it.
Small models can't even get the tool calling syntax right let alone get the content of the tool calls right.
"Le prompting" you can do with local models is just doing the work yourself with extra steps.
>>
>>
>>108270736
>I'm absolutely capable of providing a model with the context it needs to solve a problem. The difference is that if you provide opus 4.6 with the same context and ask it to solve the problem, it will do much better. It won't require 6 follow up prompts correcting it. You won't run out of context adding more information either.
Just increase the context length.
>Using a local model is like using stone tools - sure, technically, you might eventually get the job done, but why would you?
Spoken like a true boomer who thinks he's talking to a real person.
Again, the problem is: Most people aren't capable of using these models to their fullest potential to begin with. 99% of what they ask it to do are things the 16B or 20B models do just fine, but you've become lazy just asking them to do everything for you that you forgot that most of it is being abstracted out. So you think it's "stone tools" when it's more like "paying for a tradesman to do your work for you".
>>
>>108270754
Seethe, mald, cope, I'm not the shiteating retard having to pay google or anthropic because I don't want to include an extra sentence or two in my prompts.
Sorry you're fucking stupid, probably like 70 and thinks these models are magic, too.
>>
>>
>>
>>
>>108270721
Thanks. I just used gemini to tell me more about setting-up and deploying a specialized local llm. Man, this sounds great, and this is actually what I need. I need to do a lot of work related to laws/regulations/standards and if I could get the tiny model that just does this one specific thing, targets these specific regulatory frameworks that i need, and does nothing else at all - that would be a banger for me. Gemini told me I could also set some "temperature" to like zero or something to make the local model super cold and straightforward to avoid hallucination bullshit.
Will try to build one then.
>>
>>108270745
>"Le prompting" you can do with local models is just doing the work yourself with extra steps.
>I just tell my Claude based assistant what to do and it just does it.
Post like these will be studied in schools in the future as the decay of human intellect.
My prompt came with it as part of a huggingface model, I didn't do any extra work and my work is better because I got a model trained to do what I usually use it for (coding). Meanwhile you're talking to a datacenter that you have to subscribe to because you think prompting is a spook because you never read the papers:
https://www.anthropic.com/engineering/effective-context-engineering-fo r-ai-agents
Hey, look at that, even Anthropic thinks you should be doing it. It's just you who thinks it's literal magic and not part of interacting with these models.
>>
>>108270757
No, the "problem" is that nobody has a use case for shitty, inferior tools. No company is like "Man, god, I sure wish my employees had to spend extra time and effort to talk to a shitty local model and train it from scratch for the task at hand rather than just writing a small prompt with enough context to Claude, who knows the generic, non task specific stuff from its training already"
This isn't an art form and there's no 1337 cred to be gained from making things harder than they need to be.
>>
>>
File: Screenshot_2026-02-26-05-05-11-724_com.termux.jpg (863.9 KB)

863.9 KB JPG
>>108270768
This is GLM 5 at 120k tokens.
Surely if I had provided it with the right le prompt it wouldn't have generated broken sentences and become incapable of generating syntactically correct tool calls.
>>
>>
>>108270795
>I sure wish my employees had to spend extra time and effort to talk to a shitty local model and train it from scratch for the task at hand rather than just writing a small prompt with enough context to Claude, who knows the generic, non task specific stuff from its training already"
And that's why Claude sucks at it.
You'd know this if you did any real professional work of your own.
>>
>>
>>108270798
They're illiterate retards who think AI are ran by magic. Mostly because they've developed a parasocial relationship with the big models that are trained to pretend to be your friend. Then they come to /g/ where most people use their own models and try to say shit like "Le local.... le stone tools????"
Yes, normalfaggots are that stupid.
>>
>>108270794
>Hey, look at that, even Anthropic thinks you should be doing it.
no they don't. second sentence literally says:
"""Building with language models is becoming less about finding the right words and phrases for your prompts, and more about answering the broader question of “what configuration of context is most likely to generate our model’s desired behavior?"
"""
context engineering is something else.
>>
>>
>>108270795
It's a literal scientific instrument. You're acting high and mighty because you're not taking the time to learn how your own tools work, like this is something to brag about. No, it just displays that you're a fucking idiot who likely is asking the AI to do simple tasks that you had interns do for you previously.
>>108270823
I agree, there COULD be two idiots on /g/.
>>
>>
>>
>>
>>
>>108270829
The two are related, The article even says it
>In the early days of engineering with LLMs, prompting was the biggest component of AI engineering work, as the majority of use cases outside of everyday chat interactions required prompts optimized for one-shot classification or text generation tasks. As the term implies, the primary focus of prompt engineering is how to write effective prompts, particularly system prompts. However, as we move towards engineering more capable agents that operate over multiple turns of inference and longer time horizons, we need strategies for managing the entire context state (system instructions, tools, Model Context Protocol (MCP), external data, message history, etc).
I like how you had to put it in double quotes because you're used to forums or whatever shithole you crawled out of. Maybe try asking Claude to summarize the article for you instead next time, subhuman?
>>
>>108270849
This analogy doesn't even make sense. This is like using two separate tractors.
Again you're a fucking idiot who likely is asking the AI to do simple tasks that you had interns do for you previously because you don't understand your own tools. Or you buy into FOMO that only the frontier models are worth anything (Yet curiously you can't explain how, just comparisons to things that are not AI)
>>
File: r176_graph.png (366.3 KB)

366.3 KB PNG
>>108270804
>>108270794
>>108270768
I'm literally using Claude with a custom code assistant to work on optimizing a matmul kernel at the SASS level for my own inference engine written in CUDA.
This is a chart Claude made semi-autonomously an hour ago which I'm using to try to understand the assembly code generated by nvcc and then modify it to prefetch weights as the registers become unused while doing compute to hide memory latency.
Opus 4.6 is barely able to work on this with a lot of human help. Local models are worthless for these kinds of complex tasks.
What are YOU doing with your 30B local models and "two more sentences" prompts?
>>
>>
>>108270870
It's not. Your entire argument, since you seem to have forgotten it, is that "if you provide those shitty local LLMs with tens of thousands of tokens of context, they can do the job almost as well as a sloppy, imprecise prompt given to a modern proprietary model!"
So the tractor vs. oxen analogy makes a lot of sense.
>>
>>108270795
>>108270775
>>108270849
>stone tools
>oxen
>years behind
>YEARS BEHIND
Notice how they can never actually explain any technical or specifics about how it's years behind, or what they're losing by not using it? Just normalfaggot analogies about normalfaggot fields of expertise like Cars, Tractors, Plowing fields, Writing on physical objects like stone tablets.
Nah you're right, you're exactly the person who should be using the official models because they're tuned to accommodate the cleft-palate imbeciles like yourself. Please, give us a food analogy next.
>>
File: 1771141262963.png (244 KB)

244 KB PNG
>>108270876
The context is the whole conversation. I only sent that when it began to generate syntactically incorrect tool calls.
I with my garbage prompts and 80 IQ managed to make an inference engine from scratch that beats llama.cpp in certain scenarios using cloud models. What have you done?
>>
>>108270875
>I'm literally using Claude with a custom code assistant to work on optimizing a matmul kernel at the SASS level for my own inference engine written in CUDA.
This to say "I'm vibe coding something I also don't understand in CUDA, here's a chart I can't read".
>>
>>
>>108270893
See
>>108270803
>>108270875
>>108270896
for what I'm using it and what the local models fail at.
From the three supposedly SOTA cloud models (GLM 5, Minimax 2.5 and Kimi K 2.5) the only one that doesn't completely break down is Kimi but it's still worse than Claude for my use case and you will need to spend half a million dollars to run it locally at cloud speeds.
>>
>>
>>
>>
>>108270015
correction: the company loses money
AI has been yet to come close to turning a profit, these companies are all running on investor money and running at a loss. The entire AI industry is forcefeeding it into everything because they need to create artificial demand to secure even more investor money to kick the can down the road a little further. Entire industry is gonna implode and the handful of survivors will get acquired and folded into Microsoft and Apple.
>>
>>108270921
local models aren't worse because Claude has some super special secret sauce
it's because Claude throws a lot more hardware at the same problem
they're selling at a big loss right now, waiting for people to become dependent on it before they drive up the prices to make some actual money from it
>>
>>108270921
I mean, I'm an aspiring localbro, otherwise I wouldn't be working on this.
But I fear I will never be able to lay down the cloud model pipe, because probably they will always be one step ahead. Maybe in a decade they become good enough for anything you could possibly imagine.
>>
>>108270913
Reading your flowchart, that's actually pretty good, and I thought you were another boomer asking it "WHAT IS THE WEATHER TODAY" and not doing a detailed path optimization chart for a kernel.
You are the .001% of people using it correctly, then.
>>
>>108270936
ok, and? the entire point of the discussion that the even the average power user will find it very difficult to throw the amount of hardware needed at a local model for complex tasks, not that there are no use cases for local models. the answer to why non-power users use cloud over local is convenience and know-how.
>>
>>108270921
Yeah, you still don't get this isn't magic.
>>108270913
>From the three supposedly SOTA cloud models (GLM 5, Minimax 2.5 and Kimi K 2.5) the only one that doesn't completely break down is Kimi but it's still worse than Claude for my use case and you will need to spend half a million dollars to run it locally at cloud speeds.
Maybe you should be breaking this down into simpler steps for it, then? The problem, again, you think one-shot is the only way to use these models. It's not.
>>
>>108270893
Oh god, we were even talking about it. Is your context smaller than LLama's?
But you know, I'll give you what you want, another analogy. Why do I do this? When a conversation with a stupid person is going in circles, it's best to give them a mental image they can focus on.
Imagine your have two workers. Let's call them "me" and "you".
The boss gives "me" a task. A somewhat vague task. "me" realizes he doesn't have enough context to accomplish the task fully. "me" already knows similar tasks, though, just doesn't know the specifics. So "me" asks the boss what it needs to know and, with that context, produces a good result.
Now let's say the boss gives "you" a vague task. "You" starts working. You proudly proclaims that it's done. The boss looks. The result has pretty much nothing to do with what was asked. It doesn't solve the boss's request at all. "You" protests and complains that "it just wasn't given enough context". The boss asks why "you" hasn't just asked what it needs to know. You says "I apologize for the confusion and vows to do better". The boss spoonfeeds the heck out of the task to "you". Eventually, "you" manages to, more or less, fulfill the task. It's worse than "me"'s solution, though.
This repeats every time "me" and "you" get a task.
Which of these workers, do you think, will the boss like more?
>>
Is there anything else out there that's like perplexity pro? It has gone to absolute fucking shit lately, but before december or so it was insanely good. It hardly ever hallucinated because searches everything online first and foremost and acted like a RAG system combined with an LLM one. I have gemini pro and it's laughable in comparison. All the others I've tested do not compare as well since they hallucinate a lot and don't ever go as in-depth as perplexity does when it works. Ever since they started rerouting to shit models and placing arbitrarily low limits it killed my workflow.
>>
>>
>>108270966
>Which of these workers, do you think, will the boss like more?
What if
Hear me out
Not everyone is a bad manager like "you" and can give concise, detailed tasks and has no problem with structuring it in a way that even "you" can understand?
The problem is you just made an analogy that has to put yourself as a bad manager, not any of the workers as bad. You gave them a vague task and you're only happy Claude completes it because it's trained on other people giving it vague tasks like you. You could have just not given it a vague task.
You literally just described a skill issue like I'm supposed to care.
>When a conversation with a stupid person is going in circles, it's best to give them a mental image they can focus on.
I agree, so how would you feel if you didn't eat breakfast this morning?
>>
>>
>>108269970
Local LLMs are not good for 1% of the use cases. And people just flock to corporate LLM providers because of that.
I've been using duck.ai with 4o mini and honestly I don't need more except when having the AI write code for me, for which I use my company's codex sub.
>>
>>
>>108271015
How unemployed are you, holy shit.
Why, do you think, companies try to hire skilled workers? According to you, all you need are skilled bosses with infinite patience to explain to absolute fucking retards like "you" ever minute detail of every single task instead.
You can't seriously make this argument in good faith.
>>
File: Screenshot from 2026-03-01 14-03-07.png (515 KB)

515 KB PNG
>>108270949
I hope someone invents an easy way (that actually works) to make finetunes for specialized purposes like specific obscure programming languages. Then maybe local models would become good for niche things because then you wouldn't have to rely on the 0.000001% of the model's information storage capacity that has been used to store information about the thing you actually care about.
>>108270965
I'm definitely not trying to one shot it. I've been trying to make this work for weeks.
I am trying to break it down into simpler steps but in this case breaking it down into simpler steps involves understanding hundreds of lines in a 6000 line assembly file that works with an undocumented flaky undebuggable assembly language that requires encoding timing information in every instruction (the :Snn thing means stall the program counter for n cycles while the SM processes this instruction and the :Wn: means set a barrier you have to wait on till the data is fetched from memory into a register).
>>
>>108270985
>Is there anything else out there that's like perplexity pro?
My condolences, their company recently fucked everyone in the ass because they're now free for Xfinity customers. So you're experiencing the eternal september of AI models.
>>
>>108271043
>I hope someone invents an easy way (that actually works) to make finetunes for specialized purposes like specific obscure programming languages. Then maybe local models would become good for niche things because then you wouldn't have to rely on the 0.000001% of the model's information storage capacity that has been used to store information about the thing you actually care about.
Isn't this what LoRAs are supposed to be?
>that image
JFC ok yeah I'd use claude for that spaghetti.
>>
>>

holy fuck these people shills and/or retards.
It is beyond obvious that the gov/military/intelligence has access to way better AI tech than the general public.
>>
>>
>>108271078
No they don't, that's why they have to beg/threaten Anthropic
>PULHHEEEEAAAAHHHHSSSSSEEEEEEEE MAKE YOUR MODELS FOR KILLING, YEAH WE COULD TRAIN OUR OWN BUT YOU'RE SO IS SOOOOOO MUUUUCHHH BEEETTTTTEEERRRRRRRRRRRR
>I'M GONNA NATIONALIZE IT, IT'S BECOMING DOW PROPERTY
Like would a grown adult have such a public meltdown if they truly had something better?
What probably happened is they have some kind of home-rolled AI that failed at a task that an intern immediately asked Claude and got a better answer for, and they completely switched to that. They already said Maduro was captured because of Claude.
Also your image
>WE'RE IN AN AI ARMS RACE RIGHT NOW
Pretty much everyone is content to watch us put AI in charge of killer robots and fuck ourselves with it. Whatever China wants in terms of AI they simply steal after we do all the hard work, anyway.
>>
>>108271084
>Yeah but the hard part is how to build the right dataset for the LoRa. That's why labs moved onto RLVR. Because they ran out of training data.
From what I know, RLVR is practically a dead end, isn't it?
>>
>>
>>
>>
>>
>>
>>108270934
It's worth noting that Microsoft participated in every round of AI company funding except the most recent round, signaling a pullback from the AI market. Apple has been cautious the entire time. You might be right that they two of them will be in a good position to acquire the bones of the AI companies when investor money runs out and they're still nowhere close to being able to break even.
>>
>>
>>
>>
>>108269922
Local models are nowhere near as good as SOTA.
You'd also need an insane config costing more than $20,000 to run the biggest local models.
It's retarded to not use cloud models when they are so cheap and so performant.
>>
>>
>>
>>
File: 1746971751974897.png (904.7 KB)

904.7 KB PNG
>>108271476
>Local models are nowhere near as good as SOTA
wrong
>>
File: base_renamon_sample.png (887.7 KB)

887.7 KB PNG
>>108269922
1:Because local ai is dogshit.
2:Hardware costs.
3:Shitass token limits.
4:Shitass capability.
5:Shitass power bill.
/picrel is a local gen and we're only just getting there within the last year. Even the best local models and even frontier models still make mutant trashfires.
>>
>>108269922
>>108272511 (OP)
>WAAAAH WHY DO PEOPLE NOT WANT TO RUN THROUGH 900000 HOOPS AND JOIN MY TRANNYCORD?
>WAAAAAAHHH WHY TO PEOPLE NOT WANT TO INSTALL SEVERAL DOZEN PROGRAMS THAT INTRODUCE BACKDOORS FOR MALWARE AND MAKES YOUR SYSTEM HOT ENOUGH TO FRY AN EGG ON IDLE INSTEAD OF JUST ONE CLICK INSTALLS OFF THE APP STORE?
hmmm. real mystery to me buddy. YWNBAW
>>
>>
>>
>>
>>108269922
AI technology is just too volatile. It's constantly being remade and improved. I don't have a need for local image generation or anything so whatever Big Tech can come up with for programming will always be vastly superior to whatever I could run locally, even if I spent $15000 on a computer.
>>
>>
File: Screenshot 2026-02-28 151015.png (167 KB)

167 KB PNG
>>108269922
>>
>>108269922
i dont care at all about keeping my prompts private, and i don't have a supercomputer to slowly host some old model. i'd rather pay 20 bucks a month to access theirs instead. i don't care about generating anime porn or whatever, its able to very quickly and efficiently help me to compose various data analysis scripts.
>>
>>
>>
File: HB9lQygaMAEhk-V.jpg (93.8 KB)
93.8 KB JPG
>>108269922
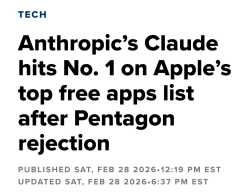
another 100 billion for the marketing budget!
>>
>>
>>108270101
ok now sell your house and spend $480,000 on this server and put it in your bedroom to even be remotely capable of handling a model on the same level. You need 2TB of RAM minimum, not even speaking on the gpu/ai accelerator requirements. https://www.lenovo.com/us/en/p/servers-storage/servers/racks/lenovo-th inksystem-sr780a-v3/len21ts0032#mod els
>>
File: __elise_fire_emblem_and_1_more_drawn_by_kutabireta_neko__293e155ef868a9c315208030d2123ebc.png (1.2 MB)

1.2 MB PNG
>>108269922
I have 64GB ddr5 and a 5090 w/ 32gb vram. What's the best model I can run locally that is redpilled on jews and can be used to coom to mesugakis?
>>
>>
>>
>>
>>