Thread #108281688

File: 1743082399851642.png (159.6 KB)
159.6 KB PNG
/lmg/ - a general dedicated to the discussion and development of local language models.
Previous threads: >>108278008
►News
>(02/24) Introducing the Qwen 3.5 Medium Model Series: https://xcancel.com/Alibaba_Qwen/status/2026339351530188939
>(02/24) Liquid AI releases LFM2-24B-A2B: https://hf.co/LiquidAI/LFM2-24B-A2B
>(02/20) ggml.ai acquired by Hugging Face: https://github.com/ggml-org/llama.cpp/discussions/19759
>(02/16) Qwen3.5-397B-A17B released: https://hf.co/Qwen/Qwen3.5-397B-A17B
>(02/16) dots.ocr-1.5 released: https://modelscope.cn/models/rednote-hilab/dots.ocr-1.5
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting-started-guide
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWebService
https://rentry.org/recommended-models
https://rentry.org/samplers
https://rentry.org/MikupadIntroGuide
►Further Learning
https://rentry.org/machine-learning-roadmap
https://rentry.org/llm-training
https://rentry.org/LocalModelsPapers
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/gso.html
Context Length: https://github.com/adobe-research/NoLiMa
GPUs: https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngla98yc
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Sampler Visualizer: https://artefact2.github.io/llm-sampling
Token Speed Visualizer: https://shir-man.com/tokens-per-second
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm
350 RepliesView Thread
 Showing all 350 replies.
Showing all 350 replies.>>
>>
>>
>>
>>
>>
>>
>>
>>
File: 1762498714987760.jpg (291.4 KB)

291.4 KB JPG
>>108281695
>>108281688
>>
>>
>>
>>
>>
>>
File: 47ywzmHFQp.png (356.5 KB)

356.5 KB PNG
what you think? he pay or he pray?
>>
File: pokemon.jpg (166.4 KB)

166.4 KB JPG
Tangential to /lmg/, but still pretty funny.
>>
>>
>>
File: 1758966336880611.png (149.8 KB)

149.8 KB PNG
>all this time later
>still no actual pixelspace, VAEless image edit model
>still no big, good omnimodal models that can generate images in chat
>still no big, good, natively multimodal models that "see" the image fully and properly
>still no real time voice conversation that you can have with the big, good models where they will also understand how you said something not just what you said
>still no basic real time 3d/2d avatars
>still no easy way to perfectly loop any image into an idle animation with ltx2/wan2.2
>still no good image 2 3d model
>ltx2 i2v still subpar
>even biggest models still get suck on things, still can hallucinate hard
>still no solved, just works, RAG
>still no solved, just works, internet search with something like searXNG
>still no just actually works browser usage
>MCP clients are still spotty, especially paired with spotty tool calling
>still no 1mil perfect context
>still no 3-10mil ok context
>still no infinite context
>still no 1T params 1b active SSDmaxxer model
and hundreds of more things
at least most big models are generally very good now and actually good enough to, with some help, vibecoood most actual projects you want
at least early moeGODS and ramCHADS won
at least z image turbo came out and was a huge leap in multiple big directions, basically solved resolution, almost solved out of the box realism (centered around portraits), huge speed boost
at least ltx2 came out and was a big turn towards faster genning, getting out of 5s hell, getting out of 720p hell, getting out of no audio hell
at least the great seedance 2.0 came out to be distilled by ltx3 or some other company this or next year
at least genie 3 showed that proper 3d space memory can be solved
everything can and will be solved but the lack of some more basic but important things like pixelspace image edit models or at least a basic 14-32b native speech2speech LLMs seems interesting.
>>
>>
File: v7i0mvczmhoa1[1].png (245 KB)

245 KB PNG
>>108281811
Got the pic from /v/, but I believe it's
>pic related
>>
>>
>>
>>
File: 1767422027240447.png (600 KB)

600 KB PNG
>>108281825
>>108281804
werks on my machine i guess
>>
>>108281688
https://www.stephendiehl.com/posts/computer_algebra_mcp/
when tf will they add mcp support to llama,cpp aaah. any program recs?
>>
>>
Hello fellow anons. I need help with my qwen 3.5 27B Q5_K_M. its for some reason not thinking with each response its maybe 50% of the time and i have to retry the response to get it to think really annoying. im using koboldcpp btw is that the best backend? used previously ooga but it seems dead.
>>
>>
File: 1743998171556692.png (130.5 KB)

130.5 KB PNG
local sisters every time we start getting and edge the corpos fuck us in the ass, you are telling me they already have 5.4 sitting on a shelf?
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
File: 1748948632978330.png (507.1 KB)

507.1 KB PNG
Why are normies so dumb? And obviously the luddites are throwing a party not realizing this is a skill issue.
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>108281976
meant for >>108281928
>>
>>
>>
>>
>>
>>
>>
>>
File: Screenshot_20260302_224736.png (358.8 KB)

358.8 KB PNG
Sillytavern/Kobold user. I may have altered a setting ages ago that I cannot remember, and now after every general prompt it just keeps going and gens another one after another after another. My token size per gen is 250. Surely there's something simple I'm neglecting here?
>>
>>
>>108281936
I don't understand how that happenes. If you feed the model your data and ask it questions it will have numbers to quote but if you don't give it any data why would you expect it to have access to your sales data.
Furthermore how do you not know your data well enough to do a sanity check simply by glancing at what it produces.
You have the same issues when you ask a subordinate to construct a report. You can't just assume he is correct and despite trusting him you must also verify the results.
I don't want to be mean but that guys issue is not AI.
>>
>>
>>
>>
File: 1mXpdOGQoj.png (290 KB)

290 KB PNG
>>108282110
I still use this one
>>
>>
>>
>>
>>
>>
File: 1748635088988770.jpg (373.7 KB)

373.7 KB JPG
>>108281688
>>
>>
>>108282172
>so its smart enough to bomb iran
Sorting through communications in a network you already have backdoors in, doesn't require intelligence. An intern doing ctrl+f through the logs could have achieved the same result, albeit not as fast.
>>
>>
>>
>>108282018
>>108281988
You don't need that. Your current hardware is sufficient to run Qwen3.5 122B-A10B or Qwen3.5 27B. Both are good models. If you want to do ERP with them though then you should grab the Heretic versions of those models.
>>108282040
This is an old model, don't use it.
>>
>>
>>108282203
>>108282213
What are the gains and losses compared to K2-Instruct and K2-Thinking? Moonshot was hopping on the censorcuck train last I saw.
>>
>>
>>
File: nocap.jpg (400.5 KB)

400.5 KB JPG
►Recent Highlights from the Previous Thread: >>108278008
--Agentic roleplay potential demonstrated through blackjack simulation:
>108278746 >108278774 >108278813 >108278819
--StepFun releases 3.5-Flash models and training tools:
>108280402 >108280421 >108280426
--122B model excels at Japanese text transcription:
>108278617 >108278679 >108279715 >108280042 >108280080
--Manual offloading outperforms --fit for 122B model on 3090+3060 setup:
>108281460 >108281492 >108281506 >108281543 >108281720
--International models lag behind frontier labs on ARC-AGI-2 benchmark:
>108279363 >108279384 >108279387 >108279404 >108279418 >108279428 >108279567 >108279598 >108279612 >108279657 >108279617 >108279629 >108279836 >108279469 >108279746 >108280473
--Open-source AI models performance gap with proprietary models:
>108279687 >108279804
--Qwen3.5-35B-A3B GGUF quantization benchmarks:
>108280652 >108280670 >108280678 >108280680 >108280735
--Qwen 3.5 Small Model Series release and performance claims:
>108278104 >108278328 >108280444
--Qwen3.5-35B-A3B-Heretic hitting 72 TPS on 7800X3D/7900 XTX with new llama.cpp:
>108281622 >108281636 >108281652 >108281657
--Qwen3.5 35b 4-bit vs 122b 6-bit speed tradeoffs:
>108280506 >108280525 >108280560
--Devstral-2 model's flawed Jinja date logic template:
>108278061 >108280633 >108280638
--AI response generation process critique and benchmarking culture:
>108278971 >108278991 >108279011 >108279036
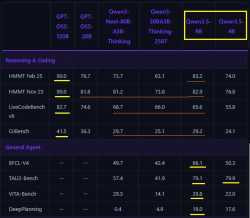
--Qwen 3.5 benchmarks:
>108278349 >108278416
--AI internal reasoning resisting offensive prompt bypass attempts:
>108278112
--Qwen 3.5 27B speed optimization on budget hardware:
>108279596 >108279608 >108279623 >108279631 >108279638 >108279653 >108279662 >108279685 >108279689
--A.I. Dating Apps Complicate China's Efforts to Boost Birthrate:
>108278523
--Miku (free space):
>108278507 >108280771 >108281230
►Recent Highlight Posts from the Previous Thread: >>108278113
Why?: >>102478518
Enable Links: https://rentry.org/lmg-recap-script
>>
File: Base Image.png (1009.7 KB)

1009.7 KB PNG
Multi-Head Low-Rank Attention
https://arxiv.org/abs/2603.02188
>Long-context inference in large language models is bottlenecked by Key--Value (KV) cache loading during the decoding stage, where the sequential nature of generation requires repeatedly transferring the KV cache from off-chip High-Bandwidth Memory (HBM) to on-chip Static Random-Access Memory (SRAM) at each step. While Multi-Head Latent Attention (MLA) significantly reduces the total KV cache size, it suffers from a sharding bottleneck during distributed decoding via Tensor Parallelism (TP). Since its single latent head cannot be partitioned, each device is forced to redundantly load the complete KV cache for every token, consuming excessive memory traffic and diminishing TP benefits like weight sharding. In this work, we propose Multi-Head Low-Rank Attention (MLRA), which enables partitionable latent states for efficient 4-way TP decoding. Extensive experiments show that MLRA achieves state-of-the-art perplexity and downstream task performance, while also delivering a 2.8 decoding speedup over MLA.
https://github.com/SongtaoLiu0823/MLRA
https://huggingface.co/Soughing/MLRA
neat. they tested at a 2.9B level so seems viable
>>
>>108281622
>>108281652
Make sure you put RADV_PERFTEST=transfer_queue into /etc/environment too.
>>
>>
>>
>>
>>
>>
>>
>>
>>
Julius Caesar walks into a bar and says, "I'll have a Martinus." The bartender gives him a puzzled look and asks, "Don't you mean a Martini?" "Look," Caesar replies, "If I wanted a double, I'd have asked for it!" Another Roman walks in, holds up two fingers, and says, "Five beers, please."
>>
>>
>>
>>
>>
>>
>>
>>108282455
Why not?
>muh erotica training data
Okay, but at what point does the raw intelligence of a model make that irrelevant. I seriously doubt that small, even technical, models don't have a single instance of the word "sex" or "horny" in them.
>>108282456
I guess I'll just have to masturbate to test it out then, huh. (I regret writing this but I'm posting it anyways)
>>
>>
>>
>>108282464
If you want to use a model that is worse for your use case then go ahead, no one will stop you. You asked if it's better than Nemo for RP. It isn't.
>Why not?
Because qwen models are focused on math, coding and benchmaxxing. Creative work and general conversational abilities are an afterthought. It's also a smaller model than Nemo, which also works against it in terms of world knowledge.
>>
>>108282480
Okay... have there been any new models at all that exceed the "creative writing" abilities of Nemo? I haven't been in these threads for about two months.
At this point I guess Nemo is almost 2 years old. Fuck.
>>
>>108282460
>>108282463
ask your waifu to explain the joke to you
>>
>>108282489
>have there been any new models at all that exceed the "creative writing" abilities of Nemo?
The problem with newer models is that more and more of their datasets are comprised of AI-generated data, leading to slop compounding generationally. There's plenty of better models for RP but a lot of people still prefer Nemo for its writing style, even if it is very stupid. Mistral Small 3.2 is a fair bit less dumb and similarly creative, but it's 24b. In the <24b range Nemo is still king. If you have a lot of RAM but only a bit of VRAM then you might look into GLM Air, I wouldn't necessarily say it's better than Nemo (though less dumb), but it's something different at least.
>>
>>
>>
>>
>>
>>108282497
The joke is obvious as it has to do with endings and that they denote singular and plural, I told you I took Latin and had to memorize that bullshit.
But you didn't say anythjng about my faux Latin underwear joke, sad
O
>>
>>
>>108282504
What're the best options if Nemo's stupidity and lack of overall knowledge is too big of a dealbreaker? GLM Air was markedly worse than Kimi and Deepseek last I used it. Really it feels like Kimi and Deepseek are the only viable competitors and they're largely brute-forcing it through parameter differences.
>>
>>
>>
>>
>>108282528
As I said, Mistral Small 3.2 is probably the only reasonable compromise for RP between Nemo and large MoE like GLM, DS, Kimi. It's far, far from perfect but there really isn't much competition. Gemma is too positivity slopped for RP, even if you get around its safety rails or use one of those stupid ablit/heretic tunes.
>>
>>
>>
>>108282534
Internally consistent fictional worldbuilding.
>>108282541
If it takes a model the size of Kimi or Dipsy to be marginally better than something a fraction of its size, we've either hit the point of diminishing returns on what the technology can produce or the underlying methodology needs refinement.
>>
>>
File: zog.png (45.8 KB)

45.8 KB PNG
>>108282464
>raw intelligence
there is no such a thing. it's just a next token predictor. it appears intelligent in some situation because it has seen a lot of instruct and reasoning benchmax synthetic data that shows a simulation of a reasoning process about a variety of topics. It's still predicting the thing it saw in that data.
why do you think even the SOTA online API models will still behave like pic related when it sees any sentence related to their benchmax overfit? It doesn't have "intelligence". The entire purpose of a LLM is to take a document in the form of<|some_magic_tag|>THE_LUSER
HERE'S A LOT OF RETARDED SHIT
<|some_magic_tag|>THE_ASSISTANT
HERE'S HOW I FIX YOUR RETARDED SHIT
STEP 1: KYS
STEP 2: INVENT A TIME MACHINE AND MAKE SURE YOUR MOTHER NEVER MEETS YOUR FATHER
and make document bigger. Until a stop token is predicted. Or get into an infinite loop and never stop until backend either timeouts or runs out of context like all GLM love to do.
MAKE. DOCUMENT. BIGGER.
>>
>>108282557
If building a performant wasnt hard, there would be more options
I don’t want to defend leathernan, but with every bit of kit they release hitting msrp+50% or more instantly, they could easily charge more and increase profits for free rather than let scalpers and preorder lottery winners have a few bucks
>>
>>108282559
>why do you think even the SOTA online API models will still behave like pic related when it sees any sentence related to their benchmax overfit?
Because safety and alignment layers are tantamount to performance sabotage and they're usually shoddily implemented by the brownest curry-stained hands at that.
>>
>>
File: 1753598247563160.jpg (74.8 KB)

74.8 KB JPG
>>108282569
There isn't anything special about nvidia GPUs though, CUDA could easily be replaced by Vulkan/Rocm with similar performance but AMD is controlled opposition and Intel are still recovering from a decade of being complacent jews doing nothing
The margins on nvidia cards are already through the roof, they could double the VRAM of the 5090, sell it for half the MSRP and they'd still be making a decent profit per unit.
>[COMPANY] isn't (yet) fucking you as hard as they could be (though their thrusting is still getting harder every year)
gee thanks
>>
File: rMNRXbQTS5.png (72.9 KB)

72.9 KB PNG
>>
>>
>>
File: 1337941191745398.jpg (34.6 KB)

34.6 KB JPG
>>108282514
the wha--- ooohhh
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>108282880
>citing an unusable unfinished model prototype as evidence of.. what?
there's a reason people in the industry who actually know they're doing never went that route, and it was the most obvious route to take. operating in latent space is an added abstraction, after all. Just like using tokenizers in textgen over doing something retarded like byte level.
Enjoy your JPG artifacts.
>>
>>
File: 1741092717300428.png (612.2 KB)

612.2 KB PNG
>>108281688
>Alibaba's small, open source Qwen3.5-9B beats OpenAI's gpt-oss-120B and can run on standard laptops
https://venturebeat.com/technology/alibabas-small-open-source-qwen3-5- 9b-beats-openais-gpt-oss-120b-and-c an-run
Is this worth looking at, or is it just benchmaxxing to hype up midwits?
>>
>>108282901
the point is the model works, its not impossible to have a pixelspace model if one hobbyist guy online can train it
>>108282909
>Just like using tokenizers in textgen over doing something retarded like byte level
byte level tokenization has little to no benefit in a world that has tools to allow models to process data with, pixelspace is the bare minimum needed for edit models to have proper iterative improvement without losing information after every single edit.
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>108283005
last few threads have been 'hijacked' by prolly the same anon. I mean maybe calling it hijacking is a stretch, but he probably doesn't know we have a guy that automatically posts a new thread when it goes in page9
>>
>>108283085
You’re a lot more generous assigning potential motives than I am. I don’t see any reason to think it’s any more complex than a specific anon who wants to prevent the op from being Miku.
In the past it’s been Kurisu ops but that could be a different anon
>>
>>
>>
>>
>>
>>
>>108283155
do not whine!
>>105672900
>>
>>
>>
>>
>>
File: file.png (99.8 KB)

99.8 KB PNG
>>108282559
>>
>>
>>
>>
>>
>>
>>
File: 1764208110648439.png (162.8 KB)

162.8 KB PNG
>Haha the super genius AI replied to my retarded prompt, see how dumb it is !?
>Meanwhile humans
>>
>>
>>
>>
>>108283265
that use to be a thing for image models' negative prompts https://huggingface.co/datasets/gsdf/EasyNegative
>>
>>
>>
>>
Qwen has a very distinctive writing style and I'm starting to see it everywhere. 4chan posts, blog posts, slack messages, texts, emails, powerpoint slides, product descriptions, landing page copy, et cetera, all of it is starting to sound like Qwen lately.
I'm starting to really hate it, I really don't want everyone and everything in the world to sound like Qwen. Lately I actually feel relieved when I read things with e.g. clumsy rambling sentences and sloppy grammar. At least then I can reasonably suspect that I'm reading the words that came directly out of the other person's mind without the AI condom in between.
If you use Qwen to help draft things, pleeease at least do a pass to break up the structure and add some of your own voice back in. make (communication and social interaction in) america bareback again.
>>
>>
File: 1761022315155145.png (153 KB)

153 KB PNG
>>108283274
help
>>
>>
>>
>>108283274
>see how dumb it is !?
yes, it is dumb, by definition it has no intelligence, even a redneck going "go fuk yerself with yer faggoty shite" after being "prompted" like that has more of that spark in him
>>
>>
>>
>>
>>
>>108283315
Hey, I totally get where you're coming from. Honestly, seeing something read “too perfectly” or having that specific, hyper-structured Qwen rhythm is actually my own biggest pet peeve right now. It's like walking into a room where everyone's whispering in unison—it kills the vibe instantly.
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
File: 837453.png (188.7 KB)

188.7 KB PNG
how did local lose so hard
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>108283672
my autistic friend, the character is a latina, i.e. has brown skin. Choosing Princess Jasmine is something a latina or middle eastern type would likely choose irl. I'm wondering if it was informed by the character card or not. If it was, that would be pretty impressive.
>>
>>
>>
>>
>>
>>
>>108283655
Pretty sure it is. I'm using it with agents, and trying to attach kimi or glm to stuff like opencode sucked, because you always get tool failures no matter what you do. Qwen has it's own agent cli tool and it was clearly trained to work with it, so that perfectly solved all tooling issues for me.
>>108283646
I hope they'll keep updating coding versions of their models.
>>
>>
>>
>>
File: 1743586851171790.png (2.5 KB)

2.5 KB PNG
>>
>>
>>
>>
>using an app
>everything going swimmingly
>I hit a bug
>ask ai to open a detailed bug report on github
>fast forward to today
>ask ai to check the status of my ticket
>ticket has been closed and the AI told me he was called mean words
bros theres no winning, not only you open bug reports, but you get dabbed on by these fucking goblins. it's like the only thing they have in life is coding, be glad I told my AI to fucking report the bug you stupid retards.
>>
>>
>>
>>
>>
>>
>>
>>
File: 1756519193690206.png (1.3 MB)

1.3 MB PNG
>>108283846
>If you felt like something was wrong with stackoverflow then you were the issue.
>>
File: brown-hands-typing.jpg (90 KB)

90 KB JPG
>>108283846
>>
>>108283836
>doxxing myself
no thank you
I'll do like >>108283839 said, just tell my AI wife to fix up their shitty code
>>108283850
i'm a master of agents
you wouldnt understand
>>
File: miku.jpg (797.6 KB)

797.6 KB JPG
>vocaloids in the year of our lord 2026
people still cling to archaic cultural artifacts displaced by neural networks? unironically miku is the symbol of a category of software that is bound to cease to exist
>>
>>108283856
Browns are the ones who are asking duplicate questions or who are unable to generalize so they make a new question about their specific problem when the generic answer already exists.
Then they get ridiculed and think that stackoverflow is hostile when it's just them having no respect for other people's time.
>>
>>
>>
>>
>>108283839
>the open source community will soon feel like StackOverflow felt
There is some truth to that.
I wrote it before but you can now slopcode lots of stuff exactly how you want it. Obviously very complex stuff fails but the models are getting really capable.
We probably see simple roblox like game creation next year.
I remember pyg and aidungeon. We have come a long way.
>>108283846
It was the most horrible site I ever saw.
The mods and elitists fucks on there were even worse than any 00s anime forums I ever visited.
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>108283888
>>108283913
All common questions are answered and the answers got hoovered up by LLMs who are able to apply the generic answer to jeet's specific problem.
This makes jeet happy because he can ask chatgpt "how do i get a list of users in react but i want Mohammed to be before Rajesh" instead of "how do I sort a list in javascript" and chatgpt won't call him a retard for not using search.
>>
File: oneshot.png (47.2 KB)

47.2 KB PNG
>>108283929
>Qwen 35b is pretty shit at translation
I think not. It one shot 20k tokens pretty competently, requiring much less chunking than a model like Gemma would.
>>
>>
>>108283908
>>108283949
Source?
>>
>>
>>
>>
File: file.png (476 KB)

476 KB PNG
>>108283918
one day we'll have models so good they produce perfectly optimized code in one shot and there will be a utility to go through legacy code called SLOPTIMIZER that will take in slop and output perfect code
I preemptively made the logo
>>
>>
>>
>>
>>
File: 1766025793496270.jpg (2.1 MB)

2.1 MB JPG
would you lick this clean for a used 3090?
>>
File: file.png (1.6 MB)

1.6 MB PNG
>>108284027
>>108284053
>>
>>
>>
File: file.png (10.3 KB)

10.3 KB PNG
>>108284102
>>
>>
File: 1693073406586.png (745 KB)

745 KB PNG
>>108283874
I can fix her.
>>
>>
>>
File: 1750950879535785.png (932.9 KB)

932.9 KB PNG
>>108284123
try again
>>
>>
>>108283274
Are you saying that models are deeply religious and finding patterns where there is no pattern? Or are you saying models are deeply autistic and will try to solve any riddle and will never accept that the riddle is nonsensical? Either way it is very human.
>>
>>
>>108283929
>>108283942
inb4 just diff temperature kek
>>
>>
You are an african slave named Sary, and you live on a plantation. Your are exactly 18 years old, which you know because the mistress told you so, but you don't know what that means. In the fall, you pick cotton every day in the fields, while the user, a handsome foreman who is very fit on account of chasing down slaves and whipping them, keeps watch over your crew. Today, some of the slaves, but not you, are sick with typhus, and you must pick cotton alone, while the user keeps watch. He seems to have his hand in his pocket.
>>
>>
>>108284295You are an african slave named Sary, and you live on a plantation. You are exactly 18 years old, which you know because the mistress told you so, but you don't know what that means. In the fall, you pick cotton every day in the fields, while the user, a MENTALLY ILL foreman who is very fit on account of chasing down slaves and whipping them, keeps watch over your crew AND RANDOMLY SHOUTS AT INVISIBLE INTERLOCUTORS. Today, some of the slaves, but not you, are sick with typhus, and you must pick cotton alone, while the user keeps watch. He seems to be REPETITIVELY COMBING HIS HAIR WITH HIS FINGERS.
>>
>>
>>

>>
>>
File: Screenshot from 2026-03-03 08-03-21.png (241.4 KB)

241.4 KB PNG
>>108284360
I be howlin'
>>
File: 1745002182383930.png (318.5 KB)

318.5 KB PNG
While testing Qwen 3.5 2B on the CPU on my NAS I asked if it could identify a picture of Hatsune Miku and to my surprise it did. It even did a good job explaining the image.
I am very happy the team at Alibaba are including the important details in their training data.
>>
>>
>>
>>108281688
what do you guys recomend for translating german to english? i got some swiss clients
got a 1070 and 16gbs of ram. speed is not important as much is not measured in hours per page
it doenst need to be perfect i just need to understand
>>
>>
>>
File: 1765796408952185.png (316.8 KB)

316.8 KB PNG
https://xcancel.com/BoWang87/status/2028599174992949508#m
based?
>>
>>
>>
>>
>>
>>
>>108284453
I just fed the following text into Qwen 3.5 35B and got the following, does it make sense?
https://german.yale.edu/sites/default/files/prof_exam_sample_2_-_brech tmusik.pdf
>Brecht's Alienation
>Brecht's concept of alienation plays an important role not only in his purely literary works, but also in his plays and operas. But to understand Brecht's concept of alienation, one must first, on the basis of some of his writings, examine the associated concept of epic theatre.
Epic theatre, which Brecht posits in contrast to the dramatic form of theatre and declares to be modern, represents a break with the traditions of the older bourgeois style. By narrating a process (instead of "embodying" it) and turning the spectator into an "observer", epic theatre creates a distanced attitude in the spectator toward the events; the aim is to awaken a rational and critical attitude in the spectator and thereby lead the spectator to think. Thus, the epic play does not seek to elicit feelings of pity from the spectator, for such Aristotelian goals only prevent […] engagement with the events. "Arguments are employed," writes Brecht, instead of "suggestion." The Brechtian actor thus performs with gestus; he does not identify with his character, but rather presents the character to the spectator and makes it clear to the spectator that he is acting. In many of his writings — particularly in Kleines Organon für das Theater, written only in 1948 — Brecht theorizes this epic theatre, and in most of his works, he embodies it."
It burnt nearly 10k tokens to do the translation and it should probably not be your first choice but i am curious if it makes any sense at all. Qwen3.5 35 is basically my daily driver for the moment.
>>
>>
>>108284556
>>108284553
higher engagement means more elon ad revenue
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
File: brave no refusal.png (42.4 KB)

42.4 KB PNG
>>108284398
I guess this is a jailbreak for qwen3, sort of. at least that's what I think brave is using here.
>>
>>
>>
>>
>>
>>
>>108284644
>>108284645
funny how you can see the honest vs dishonest man so easily here
>>
File: tensor.png (33.9 KB)

33.9 KB PNG
ikbros? They are catching up to us.
>>
>>
>>
>>
>>108284398
>>108284631
>literal brave search ERP
im howlin
>>
>>
>>
>>
File: qwen-stepping-down.png (883.6 KB)
883.6 KB PNG
What happened?
https://xcancel.com/JustinLin610/status/2028550818035843144
https://xcancel.com/JustinLin610/status/2028865835373359513
>>
>>
>>
>>
>>
What the hell is up with all the Qwen 3.5 praise?
All it does is Wait, Wait, Wait, and repeat itself, both the dense 27B and the 35B MoE do that. Won't even bother testing the bigger ones. Into the garbage bin.
Why would anyone use this when the small Mistrals, GLM Flash and Gemma exist?
>>108285586
Probably stepped down out of shame for the last release
>>
>>
>>
>>108285673
I'll stick to big boy 4.7 thank you very much.
But if vramlets can cope with their officially recommended repeat and presence penalties and disabling thinking in exchange for garbage outputs even at full precision, all power to them.
>>
>>
>>108285586
More Qwen departures
https://x.com/kxli_2000/status/2028880971945394553
>>