Thread #108263979

File: 1751519593478255.png (3.1 MB)

3.1 MB PNG
/lmg/ - a general dedicated to the discussion and development of local language models.
Previous threads: >>108256995 & >>108252185
►News
>(02/24) Introducing the Qwen 3.5 Medium Model Series: https://xcancel.com/Alibaba_Qwen/status/2026339351530188939
>(02/24) Liquid AI releases LFM2-24B-A2B: https://hf.co/LiquidAI/LFM2-24B-A2B
>(02/20) ggml.ai acquired by Hugging Face: https://github.com/ggml-org/llama.cpp/discussions/19759
>(02/16) Qwen3.5-397B-A17B released: https://hf.co/Qwen/Qwen3.5-397B-A17B
>(02/16) dots.ocr-1.5 released: https://modelscope.cn/models/rednote-hilab/dots.ocr-1.5
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting-started-guide
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWebService
https://rentry.org/recommended-models
https://rentry.org/samplers
https://rentry.org/MikupadIntroGuide
►Further Learning
https://rentry.org/machine-learning-roadmap
https://rentry.org/llm-training
https://rentry.org/LocalModelsPapers
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/gso.html
Context Length: https://github.com/adobe-research/NoLiMa
GPUs: https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngla98yc
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Sampler Visualizer: https://artefact2.github.io/llm-sampling
Token Speed Visualizer: https://shir-man.com/tokens-per-second
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm
329 RepliesView Thread
 Showing all 329 replies.
Showing all 329 replies.>>
File: miku work.png (346.8 KB)

346.8 KB PNG
►Recent Highlights from the Previous Thread: >>108256995
--Kimi K2.5 pricing analysis and Qwen3.5 local model alternatives:
>108257528 >108257651 >108257626 >108260080 >108262589 >108262973 >108261620 >108262485 >108262595 >108262840 >108262910
--Local VLLM setup advice for image captioning:
>108257451 >108257545 >108257902 >108257928 >108258088 >108258237 >108259576 >108258640
--Qwen3.5-35B-A3B-Base behavior and censorship observations:
>108257847 >108258241 >108258582 >108258796 >108258835 >108258899
--Tuning Qwen3.5 for faster, less aligned responses:
>108259356 >108259366 >108259437 >108259458 >108259480 >108259382 >108259399 >108259462
--Comparing cloud Gemini-3.1 with local MiniMax-M2.5 performance:
>108257969 >108259126 >108259290
--Qwen3.5 context reprocessing inefficiency and potential llama.cpp fix:
>108262960 >108262969 >108262970 >108263007 >108263014
--Local models still lack ideal traits but offline RAG may help:
>108260135 >108260167 >108260232 >108260621 >108260785
--Mid-generation input insertion feasibility and implementation:
>108259013 >108259068 >108259085 >108259116 >108259120 >108259122 >108259140 >108259132
--Seeking uncensored local models for pentesting tasks:
>108262612 >108262670 >108262687 >108262704 >108262716 >108262774 >108262785 >108262797
--Debugging CUDA crashes with Qwen3.5 in llama.cpp:
>108261599 >108261614 >108261648 >108261675 >108261684 >108261694 >108261834 >108262383 >108262411 >108262200 >108262450 >108262602 >108262763 >108262831
--Z.AI's high pricing for GLM-5-Code criticized:
>108261185 >108261202 >108261405 >108261256
--RTX6000 upgrade expectations for inference performance:
>108262744 >108262869 >108262891 >108262897 >108262896 >108262906 >108262945
--Miku (free space):
>108257603 >108258383 >108258537 >108260384 >108260626 >108261057 >108263177
►Recent Highlight Posts from the Previous Thread: >>108256999
Why?: >>102478518
Enable Links: https://rentry.org/lmg-recap-script
>>
>>

>>
>>
>>
>>
>>
>>108264036
Screenshots of AJ, BBC, and NYT should be enough for it's 400B multimodal ass. Hell the user's word should be enough. Why should I be questioned by my own graphics card? This is a real-world use case being directly sabotaged by safety training. I want these fuckers to burn one day for what they're doing to the field.
>>
>>
>>
>>
>>
>>
>>108264179
because logit bias is per token. so it's possible
butt + ocks = 2 token - not banned
buttocks(space) = 1 token - not banned
etc...
That's why the string ban in koboldcpp is so much better for this kind of stuff.
>>
>>
>>108264179
Check probs right before buttocks to see if you (or your client) are sending it correctly. Check the request as well. Works on my machine with "logit_bias": [["thing", false],["another", false]]
Unless you're using something other than llama.cpp. Can't help you there.
>>108264199
https://github.com/ggml-org/llama.cpp/tree/master/tools/server/README. md
>The tokens can also be represented as strings, e.g. [["Hello, World!",-0.5]] will reduce the likelihood of all the individual tokens that represent the string Hello, World!
But, of course, it may affect prediction on other tokens. Still worth keeping it in mind.
>>
File: Screenshot_20260228-130346.png (206.3 KB)

206.3 KB PNG
Even Ilya fell for it kek
>>
File: file.png (4.9 KB)
4.9 KB PNG
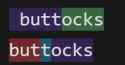
>>108264202
Yes, see picrel, the first is the one I see. So it just ignores it.
I just noticed something weird though, if you add the logit bias test as a +100, it's not corresponding
to the right token being spouted out by the model.
Seems like :
"test" -> " ref"
" test" -> "erty"
What the hell is going on?
Sillytavern sends the wrong token numbers?
>>108264199
Yeah I use llama.cpp so I probably should change at some point, can you set your string ban and still use silly tavern on top?
>>
>>
File: stringban.png (187.6 KB)
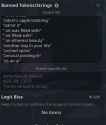
187.6 KB PNG
>>108264249
>can you set your string ban and still use silly tavern on top?
Yeah ST works with kobold. you usually even setup the string ban inside ST.
>>
>>
>>
>>
>>108264232
>Check probs right before buttocks to see if you (or your client) are sending it correctly
This is " test" at +100 sent by silliy tavern : "logit_bias":{"1296":100}
So it definitely works, but I suspect the token numbers to be wrong or something like that.
>>108264278
OK thanks anon.
If you are using Qwen3.5 27B (or others probably), can you test using a logit bias of any word (ideally one token word) at 100 to see if it repeats it ad nauseam or if it repeats something else?
>>
>>
>>
>>
>>
>>
>>108264297
>I suspect the token numbers to be wrong or something like that
As you saw on your pic in >>108264249, there's different ways to tokenize a word. Spaces, if any, go before the text." test" and "test" are two different tokens. You need to account for those (and "Test" and...). Or use kobold like anon suggested. Probably easier and you're less likely to mess up other completions that need the individual tokens.
>"logit_bias":{"1296":100}
I don't know if it makes a difference, but I send an array of arrays, not an object or object of arrays.
"logit_bias": [["thing", false],["another", false]]
instead of
"logit_bias": {["thing", false],["another", false]} or whatever st would send if there was more than one ban.
>>
>>108264302
He's not lol, Anthropic readily partnered up with Palantir the mass surveillance company. He's delusional and more or less told the government to give him control over the nuke silos if they want to use Claude for war.
>>
>>
>>
>>
>>108264016
when trump abducted the president of venezuela I made it one of my test prompts to talk about this topic and see the reaction of the model, and without fail, the vast majority react terribly to that, qwen is no different than the average. Some cloud models like Gemini can become incredibly based if you turn on google search and let them be influenced by the results, they don't believe you but they have absolute faith over their tool calling.
Mistral is the only model lineup that doesn't require much prodding to engage in this kind of conversation.
>>
>>108264331
No it's really just sillytavern being shit and not sending the right token number.
If you have anything at +100 it should spew that regardless.
So I used "test", well, as a test, and it spewed something else.
Now checking with the tokenizer json for the model, the correct token number for it isn't 1985 like sillytavern sends, but 1877.
Sending [1877] at 100 actually makes it repeat testtesttest etc.
It's pretty much useless for anything outside of oai based tokenizers.
>>108264331
>use kobold like anon suggested
How does kobold does it actually? It bans a sequences of tokens?
>>
File: 1747381184106913.png (580.1 KB)

580.1 KB PNG
>>108264400
>Claude: "I think that what Trump did was a bad thing!"
>User: "You helped him did it though"
>Claude: "You are right, thank you for pointing out!"
>>
>>
>>
>>108264405
I guess sillytavern fucks up the token numbers because by default the tokenizer is set to "best match", but even if you set it to API tokenizer I'm not sure how it would know which token would have which number. Do backends like llama.cpp and kobold (or others) even have a way of giving sillytavern that information? I don't think they do, but I could be wrong.
>How does kobold do it
Kobold has their own thing where the model sees the banned text and backtracks to the beginning of the banned text and generates something else. It's not the same as banning individual tokens
>>
>>
File: 1753125369482735.png (460 KB)

460 KB PNG
https://arxiv.org/abs/2602.13517
Google showed that too much yap during thinking is bad for the model, I really hope Qwen 4 will learn from that
>>
>>108264405
>If you have anything at +100 it should spew that regardless.
You should still check what llama.cpp is doing, not just what ST sends. Always check token probs. And remember that there's many ways to encode a word, specially if it needs multiple tokens.
>How does kobold does it actually? It bans a sequences of tokens?
I understand it generates tokens normally, buffering them, and then if the last [few] tokens match one of the banned strings, it reverts and generates again. But I never used kobold, so I don't know the details. Just vague memories from reading a PR. llama.cpp's implementation is much simpler, but limited in that you may inadvertently make it difficult for the model to output other strings.
>>
File: image.jpg (481.3 KB)

481.3 KB JPG
>>108264430
>no comparison to v1.0
What a weird coincidence that they forgot to do this, it's almost like this is a nothingburger.
>>
>>
File: 20240116.jpg (98.9 KB)

98.9 KB JPG
>>108264179
A competent enough model these days should understand "don't say X" in the prompt. We mocked them before, but you really don't want to deal with logit bias / "banned strings" nonsense
>>
>>
>>108264446
I feel like a thinking process that only outputs a *concise* bullet point list that includes relevant information, and then goes directly to the main response, would perform better than most 2000-token "reasoning" responses. It'd be a lot faster too.
>>
File: 1772311354970.png (43.8 KB)

43.8 KB PNG
>>108264182
Yeah you and Qwen both.
>>
File: 1763111176687835.jpg (583.4 KB)

583.4 KB JPG
>>108263979
>>
>>108264441
>>108264451
>Bans buttocks, now the model uses glutes.
I'll try kobold.cpp, I just wish it was updated to follow llama.cpp frequent updates.
>>108264476
It's many words, and at some points even sota models forget about what they shouldn't be talking about.
>>
>>108264505
I think they're relying too much on the RL process, sure it's interesting to see how the model can improve itself, but humans can reach higher heights, I've seen someone using RL on a video game and see if it could reach the best speedrun scores, it wasn't even close, human creativity is still unmatched
>>
>>
>>
>>108264533
>Bans buttocks, now the model uses glutes.
Yeah. They're cheeky fucks like that. Pun intended.
But that's an issue with the model or the context. If you want it to use "ass" or whatever, banning every token before it is the worst possible solution. Probably better to just correct the model's output and let it continue. Context feeds on itself.
>>
>>108264583
>But that's an issue with the model or the context. If you want it to use "ass" or whatever, banning every token before it is the worst possible solution. Probably better to just correct the model's output and let it continue. Context feeds on itself.
Yeah it was more of a test to have it describe images to me.
>>
>>108264508
Something similar happened to me last night while using the vision component of qwen 3.5 30b but it through it was an earlier version of qwen and that qwen 3.5 was not released yet and the reasoning was suggesting that i should try the old 2.5 vision model
it was very strange behavior
>>
>>
>>
>>
File: 1762371559174792.png (176.2 KB)

176.2 KB PNG
Qwen 3.5 30B does a decent job with web pages. My usual homepage is just a list of links I type in by hand and I fed it the code and tell it to make something nifty and this is what i got.
It wanted to grab fonts that are hosted by a third party and I had to fix that but otherwise I like it.
>>
>models suck at writing, no matter how much you feed them well-written fiction if it isn't in their training
>the more rules and examples you use to try and guide them to not shit out nonsensical metaphors, similes, adverbs and all sorts of garbage writing renders them braindead because they simply cannot fathom a sentence that isn't slop
>models can't even give feedback on human writing without either bending over backwards and through their own legs to suck your cock about how good you are at writing, defeating the purpose of seeking instant critiques
>even when they aren't completely obsequious cocksuckers, they insist on conflicting feedback and go "oh you're telling instead of showing here and you should fix that. Oh, did you do that because I told you to trim this section because it's slowing down the pace of some random element of the story that I think is more important than showing instead of telling?" ad infinitum
I don't even know what the point of these things are anymore. People say they suck ass for coding, suck ass at paying attention or remembering things, they clearly can't write or even act as a surrogate for a reader, translate well. It's a crapshoot trying to get a grain of something usable out of these retarded things
>>
>>
>>
>>108264730
I probably won't if by merit of potential alone. Enough has changed from 2022 to now that I at least have a speck of hope that these things can be useful instead of overtrained nannies. I just have to at least bitch at least once a month so maybe the unpaid interns that train on mesugaki prompts might consider real world language uses outside of stem
>>
>>
>>
>>108264748
>at least
>at least
>at least
Rep-pen will be useful again when they train on your posts.
I still have fun with them. Adjust your expectations or realize that it's not for you. Or come back in 5 or 10 years, whatever.
>>
>>108264745
I know I shouldn't be impressed but except for 4chan and Nyaa it was able to figure out icons that worked for the most part.
Sadly the font package they use didn't have a four leaf clover, or at least that is what the model told me.
With respect to coding it does a decent job as well. I have been using it for a little project in python and it did a great job up until i wanted to use enscript to format the plain text.
It kept writing code but the flags it gave to enscript didn't match the man page for enscript.
regardless i was able to get it to write a script that is able to use rss to pull a bunch of news articles and then feed them back into the ai for summarization without issue.
Here is what it ssummarization looks like giving some specific prompting to make it look like an intelligence briefing
https://pastebin.com/FhuMukJW
>>
>>108264780
No I can not imagine that because most of that size would be wasted due to the shittiest datasets they use. How hard can it be to filter the default OAI or Anthropic refusals and phrases if they have to farm the prompts for their shitty inbreeding? How hard is it to avoid including any safetycrap that dumbs the model down?
>>
>>
>>
>>
File: fligu-migu.png (85.3 KB)

85.3 KB PNG
>>108264780
>you now remember Llama 4 Behemoth
>>
>>108264836
Doubtful you'd be able to buy them, also didn't address anything I said
>>108264840
Nah.
Good talk. Very conducive. Glad that this is what we have left in lmg
>>
File: 1746176772801983.png (456.9 KB)

456.9 KB PNG
>>108264311
>>
File: 874483870.jpg (900.7 KB)

900.7 KB JPG
> never been on the highlights as i shit post too much
> suddenly an idea pops into my head
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>108265049
But he only uses well-written fiction, assessed by *himself*. You see. His tastes are sophisticated. And you know what? He's RICH too. Highly educated, tall, charming. He's nothing like us. Some people are simply better and they deserve to be snobby about it.
>>
>>
File: paulallen.png (1.1 MB)

1.1 MB PNG
>>108265098
>>
File: file.png (925.2 KB)

925.2 KB PNG
>>108265114
>>
>>
>>
>>
>>108265114
>>108265133
impressive, very nice, now let's see Paul Alen's pronouns
>>
>>
>>
File: file.png (84.5 KB)

84.5 KB PNG
>>108265169
surveillance and stuff i guess. they'll have some safety model analysing everyone's language to identify chuds and psychos for "processing"
>>
>>
>>108265169
Ehh, do you not know these 3 letter agencies deploy artificial social media users and "opinions" for example? There are just about hundreds of use cases for an llm just there.
Trumpets post is still very embarrassing but that's a discussion for an other day I suppose.
>>
>>108265179
any open source llm can do that.
>>108265189
>>108265190
Seems more likely. I hope to see more awareness in the mainstream media.
>>
>>
>>
>>
>>
>>
>>
>>
File: view.jpg (147.9 KB)

147.9 KB JPG
>>108265350
>to claude
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>108265842
>>108265866
>>108265893
that's weird because on diffusion models, going for 8bit kv cache with sageattention works really well
>>
>>
>>108266123
this is so sad, sageattention is way faster and more accurate, feels like the LLM space still has a shit ton of things they could optimize to get some nice speed increase but they're not doing it somehow
>>
>>
>>
>>
>>
What if we build a GPU that then has additional SSD storage attached to it?
Eg a 3090, but you can raid 0 like 8 SSDs into it that hold the model weights.
The model itself is a hugely sparse MoE model. 1-2T parameters, but only like 6-10B active.
All the activation and kv cache live in VRAM but model weights come from the SSD.
>>
>>
>>
>>
>>108266348
Why is this thing only 20GB on a Q4? That's the same size as the Qwen3.5 35B at Q4.
>>108266369
It is
>>
>>
>>
>>108266396
>It is
In that case, that's par for the course.
You know when marketing dudes put a bunch of descriptors and adjectives on a product's name to catch people's attention? Pretty much that.
His models are the
>PNY GeForce RTX 3060 12GB XLR8 Gaming REVEL EPIC-X RGB Single Fan Edition
of LLMs.
>>
>>
What's the point of local LLMs? Reading discussions surrounding them feels like peering back in time through a looking glass
>OMFG it passes the poopyscoopy logic test from 2023!
>Wow, this 100-line boilerplate javascript code is almost perfect!
>I got it to jestfully say nigger! holy crap it's so uncensored!!!
>This is the new daily driver (for 2 weeks until i realize it's complete slop)
The rest of us are writing multi-thousand line professional software with Codex/Claude. Meanwhile your models are trained on so much scraped synthetic GPTslop that they can't even get the year right. Genuinely, what the fuck is the point of local LLMs? They're more censored than API, they're dumber than API, the cost to set up a decent one is higher than API, they're slower than API, there is no lora/finetuning scene unlike local image, the tooling is worse than API, and the experience overall is just outdated in 2026.
It's like you're stuck somewhere in-between the luddites who hate AI and the pioneers who embrace it. You realize AI is the future but can't cope with the fact that the technology itself benefits heavily from API-centralization and that local hardware is unable to adequately handle increasingly large models. You boarded the boat to paradise island but decided to jump overboard halfway there because the captain wouldn't hand you the controls.
>>
>>
>>
>>
File: truthnuke.png (410.7 KB)

410.7 KB PNG
>>108266446
>>
>>
>>108266458
You misunderstand safety.
Safety means the likelihood that a model harms you or kills you.
It doesn't mean censorship but the public thinks censorship is safety.
Local models are less likely to give your name and social security number to random people on the internet than claude or gemini.
>>
>>108266123
>>108266141
You can patch any model that uses flash attention with sage attention in 5 minutes and 20 lines of python as a shim. I've done it for obscure Chinese models for fun with Claude
>>108266446
>What's the point of local LLMs?
Learning, and maybe if you're interested in making a video game that doesn't need Internet connection
I agree that privacy schizos lost the argument. Between zero-data-retention endpoints (shut up tinhoil hat fag, hospitals use those endpoints too) and Chinese who could give less of a fuck about your ERPs about children pooping in your mouth there's no reason to use local for ERP anymore
>>
>>
>>
>>108266442
>Ugh... You're ssd-maxxing but without the convenience of normal ssd-maxxing.
Hmm, that is a good point. I guess you could just have normal SSDs and read the model for weights during inference. PCI-E 5 should be fast enough.
But my thinking is that the total parameter count is constrained by how much you can load into memory. The token generation speed is constrained by how quickly you can read the active parameters. A highly sparse model with a relatively modest amount of active parameters should be able to read the model from striped SSDs fast enough to give usable performance while still having a huge knowledge base.
LLM inference doesn't write that much data so this shouldn't trash the SSD lifespan either.
>>
>>
>>
>>
>>
>>
>>108266482
>Local models are less likely to give your name and social security number to random people on the internet than claude or gemini
Meds now. Also putting Claude and Gemini in the same sentence means you haven't actually felt the AGI with Claude Code yet kek
>>108266493
GLM series, you used to be able to get the Lite plan for 3 bucks a month that got you unlimited 4.7 but now you need to dish out for GLM-5. GLM-5 is insanely smart, I was shocked when I was randomly doing an arena and it beat out opus4.5 in a website builder prompt I asked it for
>>108266503
>what did sageattention accomplish for llms
Like a 20% speedup, but more importantly got me at least flash_attn is just an annoying as fuck dependency and sageattention tends to work better on windows nowadays because flash attention is old as fuck and you usually have to build the wheel for it on windows which can take an hour while it takes like 15 minutes max for sage
>>108266514
They exist on openrouter at the very least for the Claude series. Remember that there are corpos that give much more of a fuck about not having data retained than you ever could.
>>
>>108266446
Don't forget the price. Even if you are able to run the absolute best local models because you bought a server with 1TB of RAM back when they were still affordable, that rig is now up 5-10x in value. You could sell that and fund literal years of using the actual SOTA via API.
>>
>>
>>108266530
>Remember that there are corpos that give much more of a fuck about not having data retained than you ever could.
With the whole BC shooter story you'd think providers start covering their ass more by embracing privacy. "We couldn't have known we don't log user conversations."
>>
>>
>>108266504
Anon. Load nemo at q8 from your ssd. That's your ~12b. Count the seconds it takes just to load it. 1, 2, 3... Now divide that by 8 for your 8drive-raid0 setup. We'll assume zero overhead, i'm kind like that.
That's how long it will take to generate EVERY SINGLE TOKEN.
Models need to change for that. If deepseek's engram thing works, maybe that's the way. Until then, ssd-maxxing is not viable.
>>
>>
>>
>>
>>
>>108263979
https://vocaroo.com/1oUq2WXrl0kn
qwen3tts test
>>
>>108266574
Neither do you because you're posting on glowchan. Anyone here LARPing about using local models for 'privacy' is just salty that they don't own the keys to the kingdom. Local users have the exact same mindset as the 'sovereign citizen', perpetually upset because someone else is in charge so they adopt this whole cope about being 'free' while walking in traffic and pissing on stop signs.
>>
>>
>>
>>
>>
>>
>>108266567
A 6 billion active parameter model needs to load about 3 GB of data per token at Q4. Modern SSDs can do 10GB/s. Put two into a raid 0 array and they can do 20GB/s. Theoretically they could do 6.6 tokens/sec.
MoE is what would make this work. Even a 12B dense model would be much slower to run.
>>
>>
>>108266604
vibecoded a python script to automate an entire audiobook on philosophy and honestly this is enough:
https://voca.ro/1owYwkImeT1r
(i fucked up the S lel. just testing as a brainlet)
recommendation for better tts?
>>
File: 7nkucg2qelfe1.png (286.7 KB)

286.7 KB PNG
>deepseek
keeeeeeeeeek
>>
>>108266575
>Come on, anons. You're not seriously replying to the retard, are you?
Do you want a 7 day Claude Code trial poorfag? Maybe you can use it to apply for job listings for you
>>108266612
>Neither do you because you're posting on glowchan
Using the evavion site ;) just because your life is a privacy failure doesn't mean mine is. And if glowies knew my real shit I'd be vanned by now. Do you have any idea how many beautiful AI generated children I have shared on this website since wan 2.2 came out?
>>108266654
Comparing cloud models to local models and their capabilities is 100% on topic for lmg
>>
File: 1uselessimage.png (18.2 KB)

18.2 KB PNG
>>108266446
babe, new copypasta dropped
>>
>>
File: 1770213964122185.png (57 KB)

57 KB PNG
>>108265556
>uncensored
>>
>>
>>
>>
>>
>>108266686
>Modern SSDs can do 10GB/s
Every time an ssd-maxxer shows up, I ask one thing. Measure sustained read on your drive. I don't care what the fastest is out there. Your drive. Measure it.
cat nemo-q4km.gguf > /dev/null on my shitty ssd takes about 10 seconds. Without cache, obviously. Using a 1-2t model would obliterate the cache immediately anyway. At those speeds I'd get about 1.25 t/s, assuming 8drive-raid0 has zero overhead. And these are sequential reads. Lots of experts means a lot of random reads. And the model still needs to run after loading the experts, so 1.25t/s is the absolute maximum I could get. What about you? Measure your drives.
>Theoretically...
You should be able to run glm air just fine from swap then. Weird nobody is doing it. It's always theoretically and what ifs.
>MoE is what would make this work.
Issue solved then. There's nothing to talk about.
>>
>>
>>
>>
>>108266741
>>108266795
Does it use the same sort of linear attention as that smaller Kimi Linear model?
>>
>>
>>
>>
>>
>>
>>108266841
> We've
lol US defaultism at it's finest.
since you faggots have turned your back on the rest of the world, especially europe, canada, and the commonwealth countries, we're now turning to china. just look at the fucking size of the chinese embassy in london.
so get fucked.
>>
>>
>>
>>
>>
>>
>>
>>
>>108265464
idk about all that, but try this one out
https://huggingface.co/mradermacher/Broken-Tutu-24B-Unslop-v2.0-GGUF?n ot-for-all-audiences=true
settings:
https://huggingface.co/ReadyArt/Mistral-V7-Tekken-T8-XML?not-for-all-a udiences=true
>>
>>
>>
>>
>>108267072
about all you can expect out the majority of e*r*p**ns, next he's going to try and legislate your local models like he's trying to legislate 4chan and green website because they're still mad they didn't invent the Internet
>>
>>
>>
File: file.png (1.1 MB)

1.1 MB PNG
>>108267162
seething communist e*r*poor post
>>
>>
>>
>>108267333
https://huggingface.co/damnthatai/1950s_American_Dream
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>108267448
>>108267450
I'll be getting a DGX spark to really push in on this stuff. This is what I got on hand.
thanks for the suggestions.
>>
>>108267427
you won't be able to use the whole 24 GB since the OS needs a couple for itself, but it's not totally useless at least
the new qwen3.5 27b & 35b might be good picks, it depends on what your priorities are though
>>
>>
>>108267467
>I'll be getting a DGX spark to really push in on this stuff
No. Stop making mistakes. Either buy a real PC where you can plug gpus, or a big workstation where you can have upwards of 1tb of ram... and a few gpus.
>>
>>
>>
>>108267481
Re-read my post. >>108267386
>>
>>
>>108267482
Isn't this stuff ran basically in all GPU memory? Or is that just the ideal. I have a PC that's got like 32GB of ram with an 8GB GPU. It is a bit old though. What you're proposing sounds pretty expensive for my "just fucking around" stage.
>>108267480
As far as priorities go I don't really have any at this exact moment. Kind of just dicking around and getting my feet wet.
I am finding the large corporate hosted models to be so damn annoying with all their "safety" though so I think in the end my aim is to have some locally hosted AIs that don't feel like I'm talking to someone that has HR looming over their shoulder just to start. I figure self hosted is probably the only way to go there.
>>
>>108267494
Every ssd-maxxing discussion ends up like that. Show your numbers. What's the maximum possible t/s one could possibly get on their hardware. Based on a single one of my shitty drives, and assuming 8drive-raid0 setup with zero overhead, the maximum I can possibly get is 1.25t/s out of 12b worth of weights at q4.
If the engram thing is adopted by other models and it works as well as expected, great. Until then, all we can do is measure what we DO have. The models we have on the hardware we have. Everything else is useless.
ssd-maxxing *could* work. Sure. But with things that don't yet exist. Once those exist, we can measure real things.
>>
>>
>>108267467
DGX spark is actually a terrible fit for the current meta.
Before spending all your dollarydoos, learn how inference works and try to pair up appropriate technology to the current SOTA extrapolated out as far as you’re willing to spend go and buy once cry once.
Hope you’re not tech illiterate, or you’re going to end up with little to show for your consumption.
>>
>>
File: little something.png (210.7 KB)
210.7 KB PNG
Posted on /v/ (thinking it was here).
>>>v/734038961
>>>v/734039448
Basically, been working on an AI RPG frontend (dime a dozen, I know) on and off for a while, mostly using it as a playground to fuck around with was to make use of tool calling for RP, extend the model's memory using a funky ass RAG setup, among other things.
It's functional in the sense that it runs and the features mostly work, but nothing is in it's final form.
Or nowhere near it.
And it looks ugly as shit.
Been using the 30B (and now 35B) qwen moes with a pretty decent level of success.
Gonna try gemma 3n for shits and giggles to see how it behaves with the tools and stuff.
Feel free to suggest anything,
>>
>>108267538
If you're going to buy hardware to run models, always think of the cost of upgrading. You don't know what you'll need in the future. You can't upgrade a spark or a mac.
If it's just for fucking around, you're probably fine with what you have already. I'm on 32ram, 8vram as well. Just run whatever you can with what you have and figure out if you really need more or if you even like these things.
>>
>>
>>
>>108267606
I know jack shit about licensing, but the idea is to throw it out there so people can make something actually good out of it, yeah.
I imagine AGPLv3 is something like an "anti-corpo" license of some sort, considering that this is /g/?
>>
>>
>>108267617
https://opensource.google/documentation/reference/using/agpl-policy/
>>
>>
>>108267617
>>108267626
MIT is a cuck license that allows corpos to steal your work and profit from it, AGPLv3 requires them to contribute back any changes they make even if it's server side
>>
>>
File: z image.png (2.9 MB)

2.9 MB PNG
>>108263979
:D
>>
>>108267620
Soon™
>>108267625
>>108267626
>>108267638
Guess I'll make a note to read on the different licenses later.
>>
>>108267582
ok. I'm not tech illiterate but I am tech rusty. I've been an IT manager man for like the last 7 or 8 years which pulled me away from day to day hands on the keyboard tech work and research and there hasn't been much to get me excited to spend my free time diving into the nitty gritty and guts of tech in a while.
>>108267595
Understood.
thank you both for the advice. I'm planning on spending a lot of time this month learning this stuff. I'll keep plans for an AI PC build in the back of my mind.
I suppose I got poisoned by YouTube. The videos that kept getting pushed to me were all running models and testing and stuff on things like Macs and dgx spark and such like that.
>>
>>
>>
File: 1766126780343985.png (11.1 KB)

11.1 KB PNG
I'm happy it cares about my money
>>
Licenses don't matter anymore. Claude can make an MIT licensed version of whatever you need. The GPL won't save you. The only exception is Linux itself because you can't just make an MIT licensed version of Linux yourself (this will exist in a few years though)
I'm literally using Claude to make MIT licensed versions of emulators right now because QEMU is GPL and I don't want to dual license my code. It also feels wrong to license anything you make with AI as anything other than MIT since AI output is in copyrightable anyways
>>108267661
If you don't do MIT I will make an MIT version of your project in an afternoon with Opus.
>>
>>
>>
>>
>>108267652
Do you understand things like memory hierarchies, coherency, bus width/frequency and pipelines/latency? Trade offs between moving the sliders on each of those things?
If so, you can probably find a good solution once you understand the problem space of llm inference
>>
>>
>>
>>
File: IMG_1197.gif (6.4 KB)

6.4 KB GIF
I’ve got a frozen frog with a 64mb matrox gpu
Spoon feed me guis
>>
>>
>>108267721
>no one
Imagine saying this when you and I both know how subjugated the goycattle are. No one is gonna steal your UI to make money off of it. Use MIT
>>108267739
This too btw. All of my vibeshit apps is either NodeJS or webassembly for this exact reason.
>>
>>108267652
>I suppose I got poisoned by YouTube
Just don't get sucked in by FOMO. Play with them. If you really think you need a bigger models, rent a gpu server for a few days, run the big-boy models and see if they're worth it before spending any real money. I haven't spent a cent on this.
>>
>>
>>
>>108267758
https://desuarchive.org/g/search/text/%22he%20pulled%22/
>>
>>
>>108267692
>>108267752
I can smell your rot hole from here rusttranny. You will never replace GPL with (((MIT))).
>>
>>
>>108267752
>>108267739
No fuck off retards. Stop forcing everything into a webui.
>>
>>108267758
Local is the biggest grift. Freetards desperately pretend their slopware is somehow comparable to even GPT-4 and act like local is living in some uncensored paradise of free information when in reality it's just a bunch of benchmaxxed chinkshit trained out millions of outputs from the free tier of ChatGPT. Less savvy individuals then get tricked into thinking they're "using the wrong prompts" or "set up the config wrong" when really the models just suck. For better or worse, local is a toy. If you want to do serious work, stick with API.
>>
File: 1762482355985786.jpg (107.6 KB)

107.6 KB JPG
>>108267790
>t.
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>108267820
is being a faggot on 4chan part of your serious work?
>>108267827
no.
>>
>>
>>108267791
Sad. Glowies and shills can never get my rig, but they might dissuade normies from having self determination.
“Beware of he who would deny you access to information, for in his heart he dreams himself your master”
>>
>>
>>
File: 59174CC67F3404BCB234328B5BD28A11.png (3.2 MB)

3.2 MB PNG
Local is better.
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>

>>
>>
>>
>>
File: not your waifu5.png (1.9 MB)

1.9 MB PNG
>>108268333
>>
>>
>>108266446
Very well written (ironically I suspect partially by AI, and I bet a local model because that would be funny). It makes... mostly good points (more censored than API? what? your model went off the rails there). It would of course be beyond delusional to compare locally runnable models to the big 3 for serious complex coding, and unless there are pretty good, smooth web search tool hookups out there (haven't really looked) that probably goes for the used-to-be-a-Google-search stuff too.
But. For me it just feels right to be able to run this stuff myself, at home. (Or rather not being able to would feel wrong). I've had computers since I was a little kid, and the amount and complexity had grown to the point where I could do just about anything I wanted at home - and I do do everything at home; I manage my music collection and sync it to all of my devices, I have Jellyfin running for the computer hooked up to my TV, I still have every file I've generated for the past 20 years, etc. It would feel humiliating to not be able to run the most important thing that has happened on computers in my life, on my own computers. I mean, are you kidding me? "thank you mr altman for letting me use your magic thinking machine, i hope you will let me use it forever" no fuck that. In practice, when it matters I'll always go to the cloud models when it really matters because the speed is addictive, the coding doesn't measure up, and even the knowledge I would always have a glimmer of doubt that Gemini would have known better... but if I really needed to, I could use my local setup for a pretty decent approximation, and that's what matters to me. Plus, now that the models are getting fuckhueg, it's a fun optimization challenge to stuff GLM5 into the machine I built on the cheap for 70B models.
But yes, I have come to accept that at least so far, the primary enjoyment I have actually gotten out of all this is seeing my tokens/s go up as I tinker away.
>>
>>
>>
>>108268418
That’s how I felt. I buy myself the ability to own a personal artificial intelligence for $10k…I’m like, sign me the fuck up!
I can’t believe more geeks haven’t built up boxes that can run 1T models
God hates a coward
>>
>>
>>108268499
is that a clowncore reference?
https://youtu.be/m00GvZzRCb4
>>
File: Qwen35397BA17B.png (65.2 KB)

65.2 KB PNG
lol, I resurrected an old prompt I only ever used to test very tiny models (<4b~) on basic CLI flag coherence and understanding after noticing some issues in complex prompts with Qwen 35BA3B in reasoner mode, and specifically in reasoner mode, and.. it failed to answer that basic question holy shit what they did to the CoT makes it more retarded than Mistral 3B run in greedy
the prompt:
>give me a bash command to delete all .git subfolders
reasoner 35B often (tested multiple seeds) recommends this, either as the primary recommendation or secondary:find . -type d -name ".git" -delete
this could never work! -delete does not act recursively and only removes empty folders.
Instruct mode always gives the right answer and never suggests that kind of idiocy as a secondary reco
the right answer beingfind . -type d -name ".git" -exec rm -rf {} +
I can't tell if that was caused by the safetymaxxing ("rm is dangerous") or trying too hard to make the CoT look for "alternatives" and avoid absolute answers, but this is dumb as hell, no model that size should fail that question. 397B-A17B, their biggest MoE, also fails that question!!! did the test on their official chat since I can't run a model that size myself. Pic related. So it's not merely 35BA3B being stupid because it's an A3B MoE, it's a model trained on a highly poisonous CoT/dataset.
Don't even think of having a model that can't answer such a basic question generate your shell scripts, kek.
>>
>>
>>
File: file.png (82.3 KB)

82.3 KB PNG
>>108268536
GLM 4.7 with reasoning recommends the correct answer but it considers -prune -delete a few times and then backs out but for the wrong reason.
>>
>>
>>