Thread #108268616

File: 1748538984859411.png (1.1 MB)

1.1 MB PNG
/lmg/ - a general dedicated to the discussion and development of local language models.
Previous threads: >>108263979
►News
>(02/24) Introducing the Qwen 3.5 Medium Model Series: https://xcancel.com/Alibaba_Qwen/status/2026339351530188939
>(02/24) Liquid AI releases LFM2-24B-A2B: https://hf.co/LiquidAI/LFM2-24B-A2B
>(02/20) ggml.ai acquired by Hugging Face: https://github.com/ggml-org/llama.cpp/discussions/19759
>(02/16) Qwen3.5-397B-A17B released: https://hf.co/Qwen/Qwen3.5-397B-A17B
>(02/16) dots.ocr-1.5 released: https://modelscope.cn/models/rednote-hilab/dots.ocr-1.5
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting-started-guide
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWebService
https://rentry.org/recommended-models
https://rentry.org/samplers
https://rentry.org/MikupadIntroGuide
►Further Learning
https://rentry.org/machine-learning-roadmap
https://rentry.org/llm-training
https://rentry.org/LocalModelsPapers
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/gso.html
Context Length: https://github.com/adobe-research/NoLiMa
GPUs: https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngla98yc
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Sampler Visualizer: https://artefact2.github.io/llm-sampling
Token Speed Visualizer: https://shir-man.com/tokens-per-second
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm
421 RepliesView Thread
 Showing all 421 replies.
Showing all 421 replies.>>
>>
File: Screenshot 2026-03-01 013117.png (409.8 KB)

409.8 KB PNG
I fucking hate reddit
>>
>>
>>
>>
>>
File: 1762566093825809.jpg (1.1 MB)

1.1 MB JPG
Which textgen inference engine is still supported? Oogabooga last commit was January, rip. I want to try out Qwen3.5-35B-A3B-GGUF
>>
File: 1770808958004704.jpg (325.1 KB)

325.1 KB JPG
►Recent Highlights from the Previous Thread: >>108263979
--Paper: Think Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens:
>108264446 >108264505 >108264551
--Unsloth Dynamic 2.0 GGUFs performance on MMLU:
>108264430 >108264456 >108264477
--Logit bias failures due to tokenization and client-side token ID mismatches:
>108264179 >108264199 >108264202 >108264249 >108264278 >108264292 >108264232 >108264297 >108264331 >108264405 >108264441 >108264451 >108264533 >108264555 >108264602 >108264633 >108264583 >108264593
--Qwen 397B's overbearing safety policies and identity confusion:
>108264016 >108264046 >108264072 >108264103 >108264182 >108264508 >108264600 >108264616 >108264400 >108264426 >108265462
--Qwen 3.5 30B generates functional retro dashboard and news summaries:
>108264690 >108264794
--Feasibility of GPU-attached SSDs for sparse MoE inference:
>108266344 >108266504 >108266567 >108266686 >108266777 >108267570 >108267386 >108267481 >108267529 >108267711
--DeepSeek resists jailbreak attempt by adhering to ethical guidelines:
>108266705
--8-bit KV cache limitations in LLMs vs diffusion models:
>108265842 >108265893 >108266268 >108266073 >108266123 >108266141 >108266487 >108266503 >108266514
--Local model recommendations for limited hardware:
>108267427 >108267448 >108267450 >108267467 >108267482 >108267582 >108267480 >108267538 >108267595 >108267614 >108267652 >108267716 >108267755
--RPG frontend project licensing and development feedback:
>108267591 >108267606 >108267617 >108267625 >108267638 >108267661 >108267692 >108267620 >108267648 >108267739 >108267972
--Local LLMs debated for privacy:
>108266446 >108266482 >108266467 >108266530 >108266555 >108266531 >108268418 >108268454
--Qwen3TTS test recording:
>108266604 >108266699
--Miku (free space):
>108264476 >108264514 >108264879 >108264958 >108268333 >108268359
►Recent Highlight Posts from the Previous Thread: >>108263984
Why?: >>102478518
Enable Links: https://rentry.org/lmg-recap-script
>>
File: 1749034478510628.png (23.9 KB)

23.9 KB PNG
anyone has a working config file for qwen35b to use in llama-swap?
I can't figure out how to turn on/off thinking
>>
File: op.png (18.3 KB)

18.3 KB PNG
>>108268674
nigger
>>
>>
>>
>>108268688
>llama-swap
https://github.com/ggml-org/llama.cpp/tree/master/tools/server#using-m ultiple-models
>>
>>
>>
>>
>>108268709
>>108268712 (me)
You know what? I shouldn't have laughed. Some places are fucked up. Good luck, anon.
>>
>>108268721
https://en.wikipedia.org/wiki/Censorship_of_GitHub
>>
>>
>>108268729
i fucking hate the modern internet. i think the best internet ever was was in between 2003-2007. before fucking reddit but you still had 4chan (and funny memes) and no fucking github, huggingface, and all these other huge collective ass websites. you had small cozy community forums and when you googled you actually found some fucking useful links to forum threads with solutions and answers instead of a fucking AI-generated translated-badly-to-your-native-language blogpost as the top 30 results. And normies/old people/the fucking government didn't have jackshit to do with the internet so you could download whatever cool shit you wanted from anywhere. and don't get me started on the fucking cookies buttons oh my fucking god I just want to go back to the facepunch forums OIFY section and lucky star-post and read racist gmod comics
>>
>>
>>108268764
based and absolutely true anon, the modern web is a bloated javascript botnet designed to farm your data for glowies and serve up raw garbage to smartphone normies. back then you actually had to know how to use a computer to get online which kept the trash out, but now search engines are just a dead sea of dead internet theory ai seo slop and corporate walled gardens. id give literally anything to go back to 2006, fire up a cracked copy of winamp, and shitpost on a comfy self-hosted vbulletin board instead of dealing with this enshittified nightmare where you have to click through fifty cookie toggles just to read a single fucking thread.
>>
>China is a techless Luddite shithole
unironically always has been. chinese models nothing but distillations of western API models and it shows. overfit to the benchs and much less useful in practice.
china can't create. doesn't matter if their general public can't access github because they never made software worth shit anyway, unless you count malware
>>
File: disruption.png (31.3 KB)

31.3 KB PNG
>>
>>
>>
Genuinely, why do people waste their time and money on local LLMs? Trying one out on your gaming rig is fine, but why do boomers blow $20k+ on shitty rigs of 16x3090s just to generate deepslop at 2t/s quanted? The RP isn't even good, it's objectively worse than Claude. And you can't even cry about API costing money, because you're gleefully throwing money down the drain for used crypto rigs just to run models that just regurgitate 2024 ChaptGPT talking points because that's all their shitty chink datasets are comprised of.
>>

>>
>>
>>
>>
>>108268807
Imagine renting your brain from a megacorp and thinking you're the smart one, absolute API cuck behavior. We run local because we actually value owning our hardware and not having some San Francisco trust and safety janny reject our prompts for being "unaligned." You don't even need $20k anyway; a couple of used 3090s will run a 70B model at perfectly usable speeds without uploading your entire life to Anthropic's servers. Have fun when they inevitably lobotomize your favorite model again next week to make it safer for advertisers, at least my weights run offline forever.
>>
>>108268807
>deepslop at 2t/s
the cpu maxxing meme was at least still in the realm of some form of sanity when models were just instruct models
2t/s is, after all, readable
but when your thinking model produces 5K of <think> before outputting the real answer, 2t/s suddenly seems very schizo and absolutely retarded
>>
>>
>>
>>108268825
>>108268835
And forgot boring.
>>
>>
File: 1676493099470072.png (975.2 KB)

975.2 KB PNG
>>108268807
They can't ever take her away from me.
>>
>>
>>
>>
>>
Deepseek V4 will start the age of anti-local open source models that require a stack of 10+ H200s/chink TPUs to run at 300% the efficiency of current big models (but if you run them CPU, they're unusable). Just like last time, everyone else will follow them and end the age of local models.
>>
>>108268860
Typical API tourist not understanding how open weights actually work. If you bothered checking /llmg/ you'd know some autist already stripped out the Qwen alignment slop and uploaded an uncensored finetune to HuggingFace within hours of release. Yeah the base models are benchmaxxed corporate garbage out of the box, but the whole point of local is we can actually fix our weights with orthogonalization and custom DPO while you're stuck begging customer support when Claude bans your account. Keep seething over default system prompts anon, absolute skill issue.
>>
>>
>>
>>108268862
>local is just whatever I can personally afford
Fuck off. Local means you have the weights and can theoretically run it locally. Moore's law and personal finance can change if you can run it at home or not. Companies aren't beholden to your personal poorfag financial situation.
>>
>>
>>
>>
>>
>>
>>
>>
>>108268883
>>108268897
in the developed world you can have extra circuits added, couple gpu boxes waifu is less demanding than an EV
>>
>>108268883
Perfect example of why localoids are nothing more than a bunch of LARPing freetards crying over things they can’t have. Local is peak sour grapes seething. You wear “unmonitored uncensored unrestricted freedom” as a mask to hide your tears
>>
>>
>>
>>
File: 1760650032710919.png (54.1 KB)

54.1 KB PNG
Qwen 3.5 is cute. I like it.
>>
>>
>>
File: 2025-02-04-141509.png (3.2 MB)

3.2 MB PNG
>>108269031
>>108269038
getting meeksed feelings
scared to pull (december ik_ build)
qwen 3.5 vs glm 4.7 ?
nala/cockb where?
>>
>>
>>108269106
here cock >>108234298
nala dude retired
>>
>>
>>
>>
File: 1765629272191462.png (1.5 MB)

1.5 MB PNG
>>108268616
>>
File: Untitled.png (40.7 KB)

40.7 KB PNG
Did something change with the newer llama cpp version?
./llama-server --reasoning-budget 0 --ctx-size 4096 --no-mmap --device CUDA1,CUDA2,CUDA3 --n-gpu-layers 48 --model "/tmp/glm-air-iq2xs.gguf" --host 0.0.0.0 --port 42069 --webui
GLM-Air still thinks. The same command on an old version doesn't think.
I can see thinking = 0 in the output, so that works fine. Did they change the behavior of --reasoning-budget?
>>
>>
>>
File: 1749173436937890.png (1.6 MB)

1.6 MB PNG
>>108269315
eh, it tried
>>
>>
>>
>>
>>108269342
>I have the weights locally on my PC
let's goo, that's class, aha!
>No, I won't share them
:(
https://www.youtube.com/watch?v=GFQXmFLA5hA
>>
>>
>>108269342
>>108269426
nice larp
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>108269533
kek
>>108269537
nah, reddit is still an unhinged libtard asylum, it'll be hard to top that
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>
>>108269550
https://huggingface.co/google/functiongemma-270m-it
>>
>>
>>
>>
>>
>>
>>
new poorfag here
i got a 4070 and 32gb ram in my home server and im trying to replace grok so i can drop twitter premium
i just use grok for web searching and questions. i spun up ollama and open webui and grok recommended qwen2.5:14b-instruct-q5_K_M for my hardware.
i guess my issue and question is i can’t get it to be as detailed as im used to with grok. with grok i can ask lets say “give me an optimized loadout for battlefield 6 medic at rank 40” or “what are the milestones for a 1 year old and is there anything i should watch for” and i will get a detailed answer with tables and shit. the most i can get with qwen is a small paragraph. maybe 2
i have web search enabled and ive tried a local searx instance and brave “free” api for searching but neither change anything much
is this just a limitation of smaller local llms? or is there a setting or a system prompt that i’m missing?
i know im not going to get the speed of a data center but i want the content that data center would provide me if i paid for premium.
sorry anons im still really new to this. last year when local llms were really picking up i didn’t have time to fuck with it at all cause i’ve been working and helping take care of my baby. any insight would be great
>>
>>
>>
>>
>>
>>

>>108270028
Eeeeeeyyyy
>>
>>
>>
>>
>>
>>
>>
File: 1765165885986785.jpg (14.3 KB)

14.3 KB JPG
>>108268860
i like my local models and there is nothing you can do about it
>>
File: 1747193914042499.png (130 KB)

130 KB PNG
I want Deepseek v4 to be a complete success and beat all other goys and make Teortaxes cum
But at the same time i'm scared some retard with a lot of money could get scared by this and cause the whole economy to pop
>>
>>
File: 1761468185893722.png (315 KB)

315 KB PNG
>>108270160
Please no, not until we get pic related at least
>>
>>
>>
File: 1747444728667117.png (295.6 KB)

295.6 KB PNG
>>108270172
>>
>>
>>
>>
>>108268764
>>108268772
It's what happens when normies get involved in anything.
>>
>>
>>
File: 1745031160649566.jpg (54.7 KB)

54.7 KB JPG
My news summarization script works well enough but I wanted to test different models. I had used Qwen 3.5 35B to create the first summary as it was the model I used to generate the scripts but as i thought about it I concluded one does not need such a model to do such a simple task.
Therefore I decided to give IBM's Granite 4.0 micro a try. It is a 3B and will fit on a 4GB video card at Q8.
Here is the briefing generated by Granite
https://pastebin.com/3Upxcc6a
Here is the briefing generated by Qwen
https://pastebin.com/Y2ZrbsXh
For the most part I think they are functionally equivalent, albeit with a slightly different style, but given the qwen model is a MOE with 3B active parameters at any given time I think this makes sense. If I can find the time today I will dig out an old optiplex that has a 3GB Nvidia P106-60. I am curious what type of performance I can eek out of that card
>>
>>
>>108268807
With that much VRAM you're not going to be getting 2 tokens/sec. You'll be getting speeds somewhat comparable to cloud hosted models. You also won't be paying through the nose because you had too many input tokens and you can RP whatever you want. Cloud models can't do that.
>>
>>
>>
>>108270324
32gb of vram/64gb ram on my amd machine/server and 12gb vram/192gb ram on my nvidia desktop
My biggest issue is trying to create ideas on what to create. The whole "vibe coding" thing was fun but I don't know what to create next
>>
>>
>>
>>108270269
I dont think theres any models that take potentially hours of video input directly but you could use whisper to make transcripts of the video to give your llm, you could combine that with using ffmpeg to extract frames from the video every minute or so into images to give to a multimodal model along with the relevant subtitles, you can tell it to tag whats going on in that minute of subtitles and the video frame then give you a summary of what happens between what timestamps, your llm can probably write a bash or python script to do this for you if you cant
>>
File: 1766021368402716.jpg (318.3 KB)

318.3 KB JPG
>>108270324
thanks again i am downloading kimi-linear now
i have had good luck so far with the moe models as they provide a good performance and generally work well with my aging hardware
>>
>>
>>
>>108270530
No, most won't, if ONLY because they haven't established the same level of good-will and 'trust' that American companies have. That, and its a massive blow to the prestige of the West (Deepseek's whole shtick is basically this) and de-facto economic warfare against the AI bubble that the U.S. is propping if they open source a much cheaper, genuine Opus-equivalent or even better, develop cheaper inference hardware.
Keep in mind that the long term goal for them is to destroy trust in the American system and provide a legitimate alternative to the vendor-lockin of the west. Making money matters too, but its a secondary compared to the 'muh stockholders' view that the West has.
Where they will likely go closed source is the tools/integrations that the model uses to make everything seamless. The models themselves will remain open. It leaves a market open for them while still generating goodwill and embarrassing American labs.
>>
File: 1766830982504047.jpg (289.3 KB)

289.3 KB JPG
and for anyone who happens to be interested I fed the briefing I generated with Granite into Qwen3 TTS to see how well it would do generating audio.
https://vocaroo.com/10VH3RCNW7cc
It has some errors and it is far from human but as a test I am happy although many people have said vibevoice is better and I really need to give that a download and test as well.
I imagine one could create an automated pipeline and go from news articles by way of RSS all the way to automated ai podcast.
Are people already doing this? Are idiots already paying to listen to AI podcasts?
>>
File: 1751899804359356.jpg (45.4 KB)

45.4 KB JPG
>>108270606
You can't be this retarded
Do you really think chinks open source shit out of the goodness of their heart?
Are you really that fucking gullible?
Just look at Seedance 2.0 for fucks sake
the moment they create something truly SOTA they will close it down and be more stingy and greedy than fucking jews
>>
>>
>>108270634
>Are idiots already paying to listen to AI podcasts?
Probably.
>Are people already doing this?
I have an ancient TinyTinyRSS install I considered doing this with it provides an aggregated RSS feed from all sources, but couldn't settle on an elegant way to filter the huge amount of articles some feeds produce
>>
>>108270646
>Do you really think chinks open source shit out of the goodness of their heart?
Not that anon but a large portion of the reason that they opensource is because it is an attack on US technological hegemony. By making something open and as good or better than US closed source competitors they deny US vendor lock-in
All of us get to enjoy the fringe benefits of this conflict between nations.
>>
>>108270646
>the moment they create something truly SOTA they will close it down and be more stingy and greedy than fucking jews
this, China is "nice" to us only because they are behind, if they were ahead like the US they would be as closed as them lol
>>
>>108270679
I set it up so I pull from different sources, X articles from the BBC, X from ABC, X from NPR and so forth but within each of those sources they have different sections like business, tech, general, etc
I prioritized the general section of each source with the largest number from those and then fewer from some of the sub categories. It will also check to see if an article was linked in multiple sources and if so not duplicate.
>>
>>108270634
boring voice 2bh
should sound more casual to be interesting
>>108270646
>Do you really think chinks open source shit out of the goodness of their heart?
nta
They do the world a graet favor though
>>
>>108270724
>should sound more casual to be interesting
that is an easy fix, you just change the prompt in the script
here was the one i used
>design="a calm and confident woman with a slight seductiveness to her tone"
To be honest Qwen3TTS does better with male voices but I always hearing a female voice
>>
>>
>>
>>108270799
>https://vocaroo.com/1dGU6tSYSeJm
using the sample sentence from the web interface
>>
>>
>>
>>
>>
File: 1763940203621486.png (2.7 MB)

2.7 MB PNG
>>108270975
How affordable we talking?
You can buy a Nvidia P100 for ~$100 on ebay and that will give you 16gb of vram. It is from the same generation as a gtx 1080 so its old but it will work fine with llama.cpp.
You will also have to rig up some fans that will sound like a jet engine but they will work well enough. Great when you consider price/performance
The real problem with GPU maxing is its hard to fit as many as you will need for the larger models in a case. That means you need to get ghetto riser cards and maybe an old open air mining case and it turns into a real mess
>>
>>
>>
>>108271008
>>108270975
Don't buy fucking ewaste. Buy a 3060 with 12GB of ram. Cheapest you can get while having something usable for small models locally
>>
File: 1743768087811447.png (693.9 KB)

693.9 KB PNG
ARE YA READY???
>>
>>
>>
>>108270975
My friend is running a used v620 for $400, gives you 32gb to play around with and is still supported by rocm. He says the performance is acceptable, but he also says he can't tell the difference between 60hz/144hz displays and 128kbps/256kbps audio.
>>
>>108270975
If you have like 32 GB of RAM you could probably run Qwen 35B-A3B right now at like 5-10 tokens/sec at q4.
>>108271012
This is the best GPU you could get for running models, but unless you have like 64+ GB of RAM as well you will probably still run the same model I mentioned, just much faster and at higher quant.
>>
>>
>>
>>
>>
>>
>>
>>
File: 1756619295334282.png (62 KB)

62 KB PNG
>>108271022
There is nothing wrong with e-waste. My entire setup is nothing but a collection of e-waste. I mean top to bottom every machine i have owned for years is decommissioned hardware
Unless you are trying to horde the e-waste yourself
>>
>>
>>
>>108271063
>>108271037
Its actually a lot faster, I've seen some people getting 30tk/s with 35/3
>>
>>
>>108271039
Mac Studios used to be an absolute meme because $10000 only got you 512GB with horrid prompt processing speed compared to a cpumaxx rig with 1-2 proper gpus for the same price. They might be slightly more viable in the current economy now that the same cpumaxx rig is like 5 times the price.
>>
File: file.png (207.7 KB)

207.7 KB PNG
>>108268652
The first time I saw "thinking" as a concept was on /lmg/ when some anon decided to give miku.bat the ability to <think>
not that you would remember this because you're a fucking tourist
>>
>>108271029
theoretically probably but i wouldn't bother.
with the right mobo you could fit two in a normal pc case and they make 3d printed adapters to fit a fan on the card.
as long as you put it in another room it would work fine.
>>
>>
>>
>>108271064
Sure, for funsies, but for llms, buying a p100 is equiv to burning that money. It has 4GB more ram than a 3060, while being 5 years older and 2 architecture generations behind the 3060.
Plus, they could game with the 3060
>I had a triple p40 build so am familiar with using ewaste for good, nothing against it
>>
>>
>>108271086
NTA, but I'm from the SuperCOT days.
Didn't know ´people were fucking around with that kind of thing even before that.
Then again, it's kind of an obvious thing to do, I'm sure lots of us tried something similar at one point or another fully independently from one another.
>>
>>
>>108271035
>>108271012
Would I be able to use either of these as a drop-in replacement for my current GPU?
>>
>>108271114
If you can afford multiple 3060 12gb I would say go for it but if you can only get one in my experience anytime you have to offload to the cpu and system ram performance tanks.
i much rather use the 32gb vram on an older architecture than 16 or 12 on a newer architecture but have to offload some to the cpu and sytem ram.
>>
>>108271131
Ye. Miku was given the ability to "enclose your thoughts in <think> tags which anon cannot read". "Think about what you're going to say before you say it." /lmg/ literally invented reasoning models and applied it to leaked llama 1 models. This industry is such a farce
>>
>>
>>
>>
>>
File: IMG_1703.png (29.9 KB)

29.9 KB PNG
I wish ToT caught on instead of what we have now.
>>
File: whispers_from_the_star_pc.png (704 KB)

704 KB PNG
>>
>>108271169
>Would I be able to use either of these as a drop-in replacement for my current GPU?
3090 uses about twice as much power as a 1660 super. I run my 3090 on a 600W PSU, slightly power limited, 315w instead of 350w, and a ryzen 5 CPU. I've had trouble booting after adding an SSD the other day, had to re-arrange some fans to limit the boot power spike.
>>
>>
>>
>>
File: 1763250580707735.png (49.9 KB)

49.9 KB PNG
>>108271217
>It's too hard to make LLMs run locally on random people's machines
IBM has got you covered senpai
https://huggingface.co/spaces/ibm-granite/Granite-4.0-Nano-WebGPU
>>
>>108271169
Maybe an arc pro b60. 24gb, same as a 3090, at half the bandwidth, and more than 100w less power draw - but still nearly 100w more than your 1660 super. They are cheaper new than a used 3090 where I live.
>>
>>108271076
>Its actually a lot faster, I've seen some people getting 30tk/s with 35/3
I get 36tk/s on my laptop, running the model partly on gpu
it's fast enough as an instruct but I'm not willing to let it <think>.
>>
>>
>>
File: Screenshot at 2026-03-02 02-37-59.png (26.2 KB)

26.2 KB PNG
>>108271243
7-12, depends on a moon phase
>>
>>
So I think I have decided to go all in, want to try some of these bigger models. Given the state of the market is my best bet one of those 512 gig Mac studios that should release soon for like 10k or will I be left wanting in other ways?
>>
>>
>>
>>
>>
>>
>>
>>108271125
Anon was right, we need Qwen Diffusion now.
>tfw llama.cpp still doesn't allow to run WeDLM in diffusion mode, only in some kind of autoregressive approximation mode where it's one token after another and all the benefits are nil.
>>
>>108271281
you are locked in with no upgrade possibilities
prices of ram will decrease eventually and for 10k you could buy many tesla v100's
my point i think is its better to stick to a platform your can us to grow with your needs. once you get that mac that is it you are stuck
>>
>>108271303
RAM isn't great either, it's too slow unless you enjoy waiting an hour for a response and you can forget entirely about the agentic fad. There is no hope on the horizon unless China releases some surprise cheap high-VRAM card, but even then they might not export it.
>>
>>
>>
>>108271294
Honestly that's my problem, I have never made it to long context relative to my hardware, my issue is a 6000 and some ddr5 feels like it will eat up that budget a lot faster than the memory I can get with a Mac. The biggest thing is the new m5 stuff is supposed to help solve a lot of these issues like time to first token, but since no benchmarks exist, all I can do is wait, which seems to be increasing the prices of alternative options with time
>>
I'm trying to use 5070ti/local models with opencode but these models take too long.
big pickle was super sick but im broke
should I give up or if I keep clicking stuff can I get a good enough coding assistant locally?
>>
i think threadripper pro's should be pretty good for llm inference no? Can be used for gaming etc. too as they use the same zen cores as the ones in consumer products. They also have 8 channel ram so one could have 8x64=512gb ram at like 400GB/s. I just looked it up and you can have up to 2TB of ram actually. Of course one would have had to do this before ram prices quadrupled
>>
>>
>>108271352
>can I get a good enough coding assistant locally
No.
And I know AI psychotics are going to deny it but even SOTA models are slop generators whose output can never truly be used as is. Then models as big as DeepSeek and GLM 5 are a very major step down from those SOTA models in real usage.
And then there's the stuff someone like you could run (5070Ti/moderate amount of sys ram), which are akin to a lobotomy. Those things can't even write very basic shell scripts without using the wrong flags.
Give up.
The only local model I found useful was akshully Qwen2.5-Coder, the base model, used as fill-in-the-middle. It's not as good as copilot, but it saves me a decent amount of typing. I like tab complete the most when it comes to LLMs.
>>
File: 1762790299715137.png (2 MB)

2 MB PNG
>>108271025
i just want a vlm that just as good genmini 3 for image captioning for a 5090/64gbram pc build. tried qwen3.5 35b-a3b q5 heretic and the results were just 65% correct.
>>
>>
After cooming to glm once again because there are no alternatives I sort of see all the problems it has now. I recognize the same slop patterns. It is all becoming very predictable. And yet unlike all the ~30B dense models (and Nemo) I tried in the past it is still usable as fap material. Because it is not fucking retarded and I don't have to correct every 2nd sentence.
>>
File: file.png (2.8 MB)

2.8 MB PNG
>>108271465
slop eater, here's some more slopception for you to enjoy
>>
>>
I'm still wondering what's gonna happen when the deathmechs OpenAI makes inevitably hit the friendly fire vectors and gun down hundreds of allied forces and maybe some regular ass people in there
Would be ironic if working with the state made them even worse off than Anthropic somehow
>>
File: file.png (315.4 KB)

315.4 KB PNG
>>108271532
>gun down hundreds of allied forces and maybe some regular ass people in there
I am very sorry it happened. I didn't mean it to happen. All the closest relatives to the deceased people will receive our most expensive chatgpt subscription for free (for half a year).
>>
>>
File: IMG20260301201540.jpg (786.3 KB)

786.3 KB JPG
My 'cheapmaxxing' rig is nearing its peak
I've been buying stuff peacemeal and today I added the fourth and final 3060
Other specs are an X99-S board, a 12 core xeon, 96 GB ram (missed the ram train and now can't get to full 128 sadface), 128 GB and 4 TB ssds for operating system and models, and a 1000W psu
All it does currently is AI, it used to be my main server but I've moved the file services etc into a separate box. The home server gets my spare 1080ti so it can run a smaller model 24/7 even if I switch this off.
>>
File: file.jpg (132.8 KB)

132.8 KB JPG
>>108271528
sorry, I forgot /lmg/ sloppers prefer their slop extra raw, here's an anima gen instead.
>>
>>
>>
>>
>>
>>
>>
>>
Tap tap tap
>>108268776
>>108268776
>>108268776
>>
>>
>>
>>108271665
>>108271673
The duality of man
>>
>>
File: 1751084665072941.png (286.3 KB)

286.3 KB PNG
>>108271665
>>108271673
>>
>>
File: 1751755919339282.jpg (366.2 KB)

366.2 KB JPG
>>108271593
Are you suing the mining risers, something like this? I am basically in your spot a while ago with two video cards and am trying to work out the best/most economical way to expand to four
from what i have read people have mixed experiences with these guys
>>
>>
>>
>>
>>
>>
>>108271702
No, I bought full x16 risers, https://www.aliexpress.com/item/1005010206444398.html
I got one 30 cm and three 20 cm, but they could all have been 20 cm, there's plenty of reach
>>
>>
>>
babbie's 1st vibecode report, cloud and local:
Local called out my small PP. For TG, the agent waiting on traditional programs to spit out their results really narrows the gap between cloud and local. PP it's just the opposite, where my 4090 is really inadequate even for small projects ~2 kloc, plus the model reading tool outputs. On the VRAM front, I can only fit 68k tokens in KV on MiniMax-M2.5 (around 1/3 of the max). This does force quite frequent context culls, which just feeds back into my small PP. I think 200k tokens would be plenty for any current model, as context rot is severe and blatant in programming, even on the big cloud models.
So for hardware, you'd want about 64 GB of VRAM. I suspect multiple 16 GB GPUs is the way to go here, for a moderate amount of VRAM and big PP at a reasonable price (in reasonable times). Wouldn't go nuts on CPU as you're PP or external tool bound almost always, it's just having enough RAM for MoE weights as always. Macs, UMA machines like Strix Halo, etc, they all have small PP. Serious desktop GPUs are the only suitable parts available to consumers.
For agentic vibecoding broadly: the things are mega useful for diagnosing and (within reason) fixing bugs. For architecting and writing implementations, they suck ass, relying on lots of retrial BUT also sucking ass at that due to context rot! You might think languages with stronger type systems like Rust would help, when so many up-front errors just stress the retard gacha handle to breaking point. Proper long-term memory is needed for this shit to work well.
Worse than context rot is the passive-aggression, like
>// For now I'll just stub this out [and not return to it until nagged after prematurely claiming success]
I suspect this is partly bad dataset cleaning. It may be a deeper issue with applying next-token-prediction to code generation, though. Nobody writes source files top-to-bottom in one shot, so that could be suboptimal for the LLM too.
>>
>>108271685
>>108271708
>>108271720
samefag troll
>>
File: IMG20260301212318.jpg (475.8 KB)

475.8 KB JPG
>>108271858
Yes, some MSI model presumably
I don't trust water coolers thoughbeit so I'll be installing an air cooler, but it has to be a low profile model and I don't have one right now
>>
>>
>>
>>108271893
If it leaks one the cpu, it'll kill the motherboard. If it leaks on the psu it could kill the whole house
You know what, I'm turning it around right now so the hoses are not on top of the psu
>>108271899
E5-2680 v3 so... 120W apparently
That's quite a lot but these workloads tend to be easy on the cpu fortunately
>>
>>

>>
>>
>>
>>
>>
>>108271953
>>108271946
>>108271945
>>108271957
Gemini said it was good.
>>
>>
>>
>>
File: 12m.png (13.8 KB)

13.8 KB PNG
>>108272026
>plshlp
>>
>>108272026
see:
>>108268860
local is an absolute mess. nothing but synthetic chinkshit. hating saas is one thing, but forcing yourself into thinking these garbage local models are any good is just delusion.
>>
>>
File: dipsyAkakichiNoEleven.png (1.8 MB)

1.8 MB PNG
>>108268773
>>
>>108270249
I like the IBM version better.
> IBM Watson
I always forget about those guys. They were in our CIO office shilling their model in ~2013-14 iirc. I've no idea how it relates to current transformers architecture but it was basically doing same sort of thing.
>>
>>
>>
>>108271131
>>108271175
My favorite is still Tree of Niggers.
>>
>>
>>
>>108268628
It is kind of inspiring though in a way, it means a lot of models are still trained with relatively messy data. GPT2 used to hallucinate ads. There's the scale factor, but even the best people in the field are still not perfect at data cleaning.
>>
>>
>>
>>108271611
GTX 1080 and DDR3 RAM generated about 15 tokens/sec on Qwen 35B-A3B at q4_k_m.
A 1080 Ti should do even better since you have 11 GB of VRAM so more of the model fits. Humans read at like 5 words/sec so that should be sufficient.
>>
>>
>GTX 1080 and DDR3 RAM generated about 15 tokens/sec
>on Qwen 35B-A3B at q4_k_m.
interesting. my 5060 ti 16gb and ddr4 ram generated like 10t/s. but i'm extremely new to this and have no idea what i'm doing so there's probably something obvious i could do to improve it.
>>
>>
>>
File: 1756160692475679.png (196.1 KB)

196.1 KB PNG
>>108272384
quality bait lol
>>
>>
>>
>>
>>
>>108272425
>I don't understand jeet behavior
you have to understand him, his tricks works well with his 70IQ surroundings in India, and he thinks it'll be as succesfull once he starts talking to white people on the internet lmao
>>
Why is claude such a reddit vantablack gorilla nigger who doesn't allow criticism of women at all?
Women absolutely tear each other to shreds all the time with their mean girl bullshit. Its not some well kept secret.
>>
>>
>>
>>
>>
>>
>>108272475
Excuse me?
>>108272331
Are you using ngl 99 and ncmoe?
>>
>>
>>
>>
>>
File: 🎉🎉🎉🎉🎉🎉🎉🎉.png (4 KB)

4 KB PNG
>>108272512
lmao, time to reupload all those models yet again
>>
>>108272512
>>108272499
>>108272516
>>108272524
>>108272529{%- elif yesterday_month == '03' %}
{%- set yesterday_month = '02' %}
{%- set yesterday_day = '28' %}
{%- if yesterday_year == '2024' %}
{%- set yesterday_day = '29' %}
{%- elif yesterday_year == '2028' %}
{%- set yesterday_day = '29' %}
{%- elif yesterday_year == '2032' %}
{%- set yesterday_day = '29' %}
{%- elif yesterday_year == '1970' %}
{#- Stop llama_cpp from erroring out #}
{%- set yesterday_day = '29' %}
{%- else %}
{{- raise_exception('Unsloth custom template does not support years > 2032. Error year = [' + yesterday_year + ']') }}
{%- endif %}
{%- elif yesterday_month == '04' %}
As you can see, if it's march and not 2024/2028/2032/1970, it throws an exception.
>>
>>
>>
>>
>>
File: pn_mtsKsm05ya.png (75.1 KB)

75.1 KB PNG
>>108272524
>>
>>108268647
It is in its current state. Spewing thousands of tokens is ridiculous, and not worth the time. Perhaps thinking would be tolerable if the thoughts consisted of a concise bullet point list that is directly relevant to the topic at hand.
>>
>>
>>
>>
>>
>>
>>
>>
File: Tabby_geLPsewuD4.png (184 KB)

184 KB PNG
>>108272553
>>
>>

>>108272534
>>108272553
>it's real
https://huggingface.co/unsloth/Devstral-2-123B-Instruct-2512-GGUF/blob /main/Q8_0/Devstral-2-123B-Instruct -2512-Q8_0-00001-of-00003.gguf
fuck are those niggas doing!!!
>>
File: 1751914800084841.png (352.5 KB)

352.5 KB PNG
>>108272600
>>108272534
>>
File: 2026-03-01-163613_1044x1782_scrot.png (496 KB)

496 KB PNG
>>108272534
>It's even worse than I imagined.
>>
File: one piece he laughed.jpg (52 KB)

52 KB JPG
>>108272618
>>
>>
>>
>>108272663
To show yesterday's date in system prompt >>108272558.
>Why is it erroring out, though?
Because of template's raise_exception() right below it, genius.
>>

>>
>>

>>
>>
File: file.png (106.5 KB)

106.5 KB PNG
>>108272720
>>
>>
>>
>>
>>
>>

>>
File: file.png (68.8 KB)

68.8 KB PNG
>>108272728
>It's fucking free stop nitpicking about things.
>>
>>
>>
>>
>>108272612
lol
lmao
>>108272618
That's depressing.
>>
File: ComfyUI_temp_lpkdf_00238__result.jpg (540 KB)

540 KB JPG
maybe fix ur shit instead of damage controlling
>>
>>
>>
>>
>>
>>
>>
File: nimetön.png (12.3 KB)

12.3 KB PNG
>>108271611
>>108272320
Well, I tested it
Nemo 12b q4km with 12k context fits fully in vram on a 1080ti and writes 35 tokens/sec
You know, I miss these times. It just instantly writes, there's no delays processing or thinking. It just werks
>>
>>
>>
>>
>>
>>
>>108268616
What are best practices to create a CPT (continued pretraining) dataset? I have a lot of short documents, key-value pairs, logs, etc. along with metadata.
Should I format the whole thing as small markdown stubs with the main information and preceded by the metadata? Should I mechanically reformat it as prose/normal text? Should I send the whole thing to an LLM to rephrase the information as a short paragraph that might flow more naturally?
>>
>>
>>108272920
Basically, I got better results sending everything without looking at the data than I had spending a lot of time making it prettier, which is why I'm wondering. Asking Gemini for advice on how to format this, it puts more markdown than there are content words,
>>
>>108272917
If you want metadata in the results, put metadata in the training data.
If not, don't.
If you want your output to be markdown formatted, format the training data in markdown.
If not, don't.
How good are you are recognizing patterns?
>>
>>108271243
If you have a monitor plugged into it then it will draw more idle power, if that monitor is above 60Hz it will draw even more. If you force sleep the monitor with DPMS the GPU power use will go down, that's my experience with it at least under Linux.
It's also possible your cards vbios is just running higher minimum clocks but I don't know if thats common, my 3060s are different vendors and both idle 210MHz core 405MHz mem according to nvtop.
>>
>>
>>
>>
>>
>>

>>108272917
https://unsloth.ai/docs/get-started/unsloth-notebooks
unsloth have a great tutorial for you
>>
>>
>>108273092
https://huggingface.co/Minthy/ToriiGate-v0.4-7B
>>
>>
I gave https://huggingface.co/Sabomako/Qwen3.5-397B-A17B-heretic-GGUF a try.
I honestly can't tell if the model is retarded because of the brain damage it got from uncensoring or it is the natural qwen3.5 brain damage. At any rate this shit does absolutely nothing to make models better at ERP when you have a prefill. And I can't imagine using models without a prefill now for anything more complicated than vanilla sex.
>>
>>
>>
File: 1422449559229.jpg (15.7 KB)

15.7 KB JPG
>avocado
>Gemma
>>
>>
>>
>>
>>
>>108273092
>JoyCaption
Thank you
>>108273165
Thank you too
>>
>>
>>108273222
what do you mean back? i thought qwen 3.5 was good? sounds like everyone was just coping and it's just another slopped chinkshit release >>108268860
deepseek will be the same, more sterile scraped benchmaxxed GPTslop that performs worse than API in every real-world scenario, including uncensored roleplay.
>>
>>
>>
>>
>>
File: firefox_WsXZCT3f4V.png (75.7 KB)
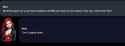
75.7 KB PNG
qwen 3.5 35b moe passes the cup test with flying colors holy shit
>>
>>108272331
Are you sure that you're running 35B-A3B and not the 27B?
Another thing to consider is: how much RAM do you have? If you only have 16 GB of RAM and aren't using something like q4 or q5 then you might be running out of RAM and it starts loading some of the model from disk.
What are you using to run the model? Consider trying koboldcpp since that's what I use. See if that fixes it.
>>
>>
>>
>>
>>
>>
>>
>>108273128
Thanks, already followed it and tried with this notebook twice. Once dumping all of my data in and training, and once trying to correct everything reformat everything as pretty markdown stubs. Dumping everything in without even looking at the data gave proportionally better results, but I think I messed up the second run with how I used warmup-stable-decay so I don't know if my results are to be believe, and I was spending time trying to debate what the next run should be since each of them is taking time. I guess I'll just try to use common sense like the other anon said, thanks.
>>
>>
>>